 Supporting Statistical Analysis for Research
Supporting Statistical Analysis for Research
4.7 Coding missing values
4.7.1 Data concepts - Conditionally created variables
In section 4.5 we examined how a test of a variable creates a results in a conditional variable. These condition variables can be used to create a new variable from two other variables, a true variable and false variable. The result variable for an observation will take the value of the true variable when the condition variable for that observation is true. Otherwise the observations will take the value from the false variable for that observation. This is visually displayed in figure 4.3.
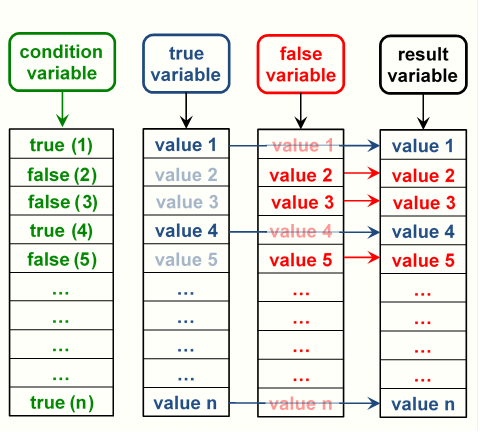
Figure 4.3: Column index of a data frame
As an example, let's consider using a conditionally created variable
to replace values of "?" with na in a variable named x.
This is visually displayed in figure 4.4.
The condition variable would be the result of a testing x for equality with "?".
The true value, what to do when x is equal to "?",
would be a variable containing na for all observations.
The false value, what to do when x is not equal to "?", would be x.
The resulting variable could be saved in the data frame as x,
overwriting the original variable x, saved with a new name,
or used for something else.
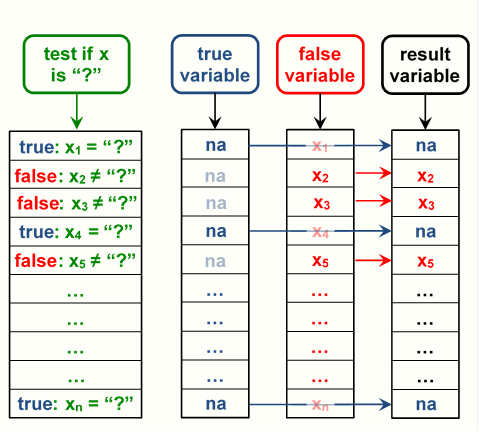
Figure 4.4: Column index of a data frame
4.7.2 Programming skills - Identifying missing data
The first place to check for information about missing data is the documentation for the data. If the data has a code book, it will often indicate values used to identify missing data.
Another approach is to visually scan the data in the data editor or a text editor. This is useful if the data set is smallish and can be open in an excel like format. This method can be difficult if the data set is large or can not be opened in a way that displays columns.
Making exploratory plots of the data is another good method to identify missing value indicators. Unusual and unexpected values become visible in plots.
4.7.3 Examples - R
These examples use the airAccs.csv data set.
We begin by using the same code as in the prior sections of this chapter to load the tidyverse, import the csv file, and rename the variables.
Note, the
lubridatepackage is also loaded for use in these examples.library(tidyverse) library(lubridate)airAccs_path <- file.path("..", "datasets", "airAccs.csv") air_accidents_in <- read_csv(airAccs_path, col_types = cols())Warning: Missing column names filled in: 'X1' [1]air_accidents_in <- air_accidents_in %>% rename( obs_num = 1, date = Date, plane_type = planeType, dead = Dead, aboard = Aboard, ground = Ground ) air_accidents <- air_accidents_in glimpse(air_accidents)Observations: 5,666 Variables: 8 $ obs_num <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, ... $ date <date> 1908-09-17, 1912-07-12, 1913-08-06, 1913-09-09, 19... $ location <chr> "Fort Myer, Virginia", "Atlantic City, New Jersey",... $ operator <chr> "Military - U.S. Army", "Military - U.S. Navy", "Pr... $ plane_type <chr> "Wright Flyer III", "Dirigible", "Curtiss seaplane"... $ dead <dbl> 1, 5, 1, 14, 30, 21, 19, 20, 22, 19, 27, 20, 20, 23... $ aboard <dbl> 2, 5, 1, 20, 30, 41, 19, 20, 22, 19, 28, 20, 20, 23... $ ground <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ...Identifying values that need to be coded as missing.
The description file for the
airAccs.csvdata set,airAccs.txt, does not provide any information on missing values.A visual scan can be done using the data browser in RStudio. Take a look at the
air_accidentsdata frame and see if there appears to be any missing data.From the visual scan of the data you can see that there are
?values in theoperatorandplane_typecolumns. (A few of the rows are displayed below.)air_accidents %>% filter(operator == "?" | plane_type == "?") %>% select("location", "operator", "plane_type")# A tibble: 40 x 3 location operator plane_type <chr> <chr> <chr> 1 Near Yarmouth, England ? Zepplin LZ-95 (air sh~ 2 Pao Ting Fou, China ? ? 3 Fuhlsbuttel, Germany ? LVG C VI 4 Venice, Italy ? de Havilland DH-9 5 Cabrerolles, France Grands Express Aeri~ ? 6 Toul, France CIDNA ? 7 New York, New York ? Sikorsky S-25 8 Rio de Janeiro, Brazil ? ? 9 Rio de Janeiro, Brazil ? Junkers G24 10 Southesk, Saskatchewan, Can~ Western Canada Airw~ ? # ... with 30 more rowsNote: the entries with
?could be changed toNAusing thenaparameter ofread_csv(). This is not done here to demonstrate techniques that operate on a single column.There are also values in the
plane_typecolumn that include?s with other text. These partial?entries will be left as they are, since there may be important information in the non-?part of the entries. The entries with only?will be changed toNA.Coding values as
NA.The
mutate()method can be used to change already existing columns or create new columns. The parameter name is the column name to be changed or added. The parameter value is what the column name is set to. We will usemutate()to replace the?values.The
if_else()function selects between two possible values for each row based on the condition value for the row.A common way
if_else()is used to to set one of the two values to be the variable (i.e. the existing value of the variable.) Then the variable remains the same except when a particular condition is met. This is how we will use theif_else()function in this example.The tidyverse conditional functions/methods do more type checking than base R functions. The tidyverse defines a set of NA_*_ values for character, real, and integer. The
NAvalue used here isNA_character_.air_accidents <- air_accidents %>% mutate( operator = if_else(operator == "?", NA_character_, operator) ) air_accidents %>% filter(operator == "?" | plane_type == "?") %>% select("location", "operator", "plane_type")# A tibble: 25 x 3 location operator plane_type <chr> <chr> <chr> 1 Pao Ting Fou, China <NA> ? 2 Cabrerolles, France Grands Express Aeriens ? 3 Toul, France CIDNA ? 4 Rio de Janeiro, Brazil <NA> ? 5 Southesk, Saskatchewan, Canada Western Canada Airways ? 6 San Barbra, Honduras <NA> ? 7 Miami, Florida Pan American Airways ? 8 Poona, India Military - Indian Air Force ? 9 Off Hampton Roads, Virginia Military - US Navy ? 10 Seljord, Norway Military - U.S. Army Air Corps ? # ... with 15 more rowsThe
?values have been changed toNA's.Other approaches to coding values as
NA.The
recode()function will replace all occurrences of a specific value,?in our example, with a different value.The
na_if()function is used to change all occurrences of a specific value,?in our example, toNA. Thena_if()function is a special case of therecode()function.# restore original values of the variables air_accidents <- air_accidents %>% mutate( operator = pull(air_accidents_in, operator), plane_type = pull(air_accidents_in, plane_type) ) air_accidents <- air_accidents %>% mutate( operator = na_if(operator, "?"), plane_type = recode(plane_type, "?" = NA_character_) ) air_accidents %>% filter(operator == "?" | plane_type == "?") %>% select("location", "operator", "plane_type")# A tibble: 0 x 3 # ... with 3 variables: location <chr>, operator <chr>, plane_type <chr>
The mutate(), if_else(), and recode()
functions are used in a large number of wrangling tasks.
Becoming familiar with them will serve you well.
4.7.4 Examples - Python
These examples use the airAccs.csv data set.
We begin by using the same code as in the prior sections of this chapter to load the packages, import the csv file, and rename the variables.
from pathlib import Path import pandas as pd import numpy as npairAccs_path = Path('..') / 'datasets' / 'airAccs.csv' air_accidents_in = pd.read_csv(airAccs_path) air_accidents_in = ( air_accidents_in .rename( columns={ air_accidents_in.columns[0]: 'obs_num', 'Date': 'date', 'planeType': 'plane_type', 'Dead': 'dead', 'Aboard': 'aboard', 'Ground': 'ground'})) air_accidents = air_accidents_in.copy(deep=True) print(air_accidents.dtypes)obs_num int64 date object location object operator object plane_type object dead float64 aboard float64 ground float64 dtype: objectIdentifying values that need to be coded as missing.
The description file for the
airAccs.csvdata set,airAccs.txt, does not provide any information on missing values.A visual scan of this data set can be done using Excel. Take a look at the
air_accidents.csvfile and see if there appears to be any missing data.From the visual scan of the data you can see that there are
?values in theoperatorandplane_typecolumns. (A few of the rows are displayed below.)(air_accidents .query('operator == "?" | plane_type == "?"') .copy() .loc[:, ["location", "operator", "plane_type"]] .head(n=10) .pipe(print))location ... plane_type 16 Near Yarmouth, England ... Zepplin LZ-95 (air ship) 63 Pao Ting Fou, China ... ? 66 Fuhlsbuttel, Germany ... LVG C VI 70 Venice, Italy ... de Havilland DH-9 89 Cabrerolles, France ... ? 100 Toul, France ... ? 110 New York, New York ... Sikorsky S-25 143 Rio de Janeiro, Brazil ... ? 169 Rio de Janeiro, Brazil ... Junkers G24 228 Southesk, Saskatchewan, Canada ... ? [10 rows x 3 columns]Note: the entries with
?could be changed toNaNusing thena_valuesparameter ofread_csv(). This is not done here to demonstrate techniques that operate on a single column.There are also values in the
plane_typecolumn that include?s with other text. These partial?entries will be left as they are, since there may be important information in the non-?part of the entries. The entries with only?will be changed toNA.Coding values as
NaNThe
assign()method can be used to change already existing columns or create new columns. The parameter name is the column name to be changed or added. The parameter value is what the column name is set to. We will useassign()to replace the?values.A
comprehensioncan be used to conditionally build a variable. The syntax for thelist comprehensionthat we will use is[<True_value> if <condition> else <False_value> for x in <variable> ]The comprehension loops through all the rows of the
variabletesting each value against theconditiongiven. IfconditionisTrue, theTrue_valueis used for that row, otherwise theFalse_value is used. Thexis used to represent the value of the variable at a row. Other variable names besidesxcan be used.A common use of a
comprehensionis to set one of the two values to be the variable being tested. Then the variable remains the same except when a particular condition is met. This is how it will be used in this example.air_accidents = ( air_accidents .assign( operator=[np.NaN if x == '?' else x for x in air_accidents['operator']], plane_type=[np.NaN if x == '?' else x for x in air_accidents['plane_type']])) (air_accidents .query('operator == "?" | plane_type == "?"') .copy() .loc[:, ["location", "operator", "plane_type"]] .head(n=10) .pipe(print))Empty DataFrame Columns: [location, operator, plane_type] Index: []Another approach to coding values as
NaNThe pandas
replace()function uses adictionaryto specify what specific value is to be change to and which variables to apply the replacements to.A
dictionaryis specified as matched pairs of object inside of the curly brackets. The:operator identifies the name (on the left side) and its paired value (on the right side.) The names are called keys because they are used to look up a value. Commas separate the entries in the dictionary. For example,{'a': 1, 'b': 2}associates 1 with the key
aand 2 with with the keyb.The
replace()function nestsdictionariesinside of adictionary. For example, the dictionary that replaces?in theoperatorvariable would be,{'operator': {'?': np.NaN}}.This associates
{'?': np.NaN}with the key (a variable name)operator. The{'?': np.NaN}dictionarytellsreplace()to change?toNaN. If other values were to be changed for theoperatorvalue, the{'?': np.NaN}dictionarywould include those with each separated by a comma. If changes to another variable were to be made, the{'operator': {'?': np.NaN}}dictionarywould include those names and theirdictionaries, each separated by a comma as well. For example,{'operator': {'?': np.NaN, '': np.NaN}, 'location': {'?': np.NaN}}would change both
?and the empty string toNaNin theoperatorvariable and?toNaNin thelocationvariable.# restore original values of the variables air_accidents = ( air_accidents .assign( operator=air_accidents_in['operator'], plane_type=air_accidents_in['plane_type'])) # new code air_accidents = ( air_accidents .replace({ 'operator': {'?': np.NaN}, 'plane_type': {'?': np.NaN}})) (air_accidents .query('operator == "?" | plane_type == "?"') .copy() .loc[:, ["location", "operator", "plane_type"]] .head(n=10) .pipe(print))Empty DataFrame Columns: [location, operator, plane_type] Index: []Conditionally create a variable when neither condition is constant.
The prior examples in this section have worked because one of the two test conditions has been a constant value,
np.NaN. In later sections you will need to choose between two variable values based on a test. Techniques that allow you to do so will be demonstrated here. These examples will replace the?in the operator withnp.NaN, but could be used to replace it with a variable that has different values for different observations.The first method will use the
zip()function inside of a comprehension. Thezip()function creates sets of observations, called tuples, that a comprehension can iterate through.# restore original values of the variables air_accidents= ( air_accidents .assign( na_var = np.NaN, operator=air_accidents_in['operator'])) # new code air_accidents = ( air_accidents .assign( operator=[na if operator == '?' else operator for operator, na in zip(air_accidents['operator'],air_accidents['na_var'])])) (air_accidents .query('operator == "?"') .copy() .loc[:, ["location", "operator", "plane_type"]] .head(n=10) .pipe(print))Empty DataFrame Columns: [location, operator, plane_type] Index: []The next method uses
np.where()to select between two possible values. The parameters are the condition, true value, and false value. Note,np.where()is different than thepd.where()method.# restore original values of the variables air_accidents= ( air_accidents .assign( na_var = np.NaN, operator=air_accidents_in['operator'])) # new code air_accidents = ( air_accidents .assign( operator=np.where( air_accidents['operator'] == '?', air_accidents['na_var'], air_accidents['operator']))) (air_accidents .query('operator == "?"') .copy() .loc[:, ["location", "operator", "plane_type"]] .head(n=10) .pipe(print))Empty DataFrame Columns: [location, operator, plane_type] Index: []The
pd.mask(),pd.where()andnp.select()are other methods and functions that are useful when creating variables based on a condition.Using subsetting to code values as
NaNSubsetting is done by using the
loc[]method to subset conditionally on theoperatorvariable having the value?. All of the subsetted values are then changed toNaN.# restore original values of the operator variable air_accidents['operator'] = air_accidents_in['operator'] air_accidents.loc[air_accidents['operator']=='?', 'operator'] = np.NaN (air_accidents .query('operator == "?" | plane_type == "?"') .copy() .loc[:, ["location", "operator", "plane_type"]] .head(n=10) .pipe(print))Empty DataFrame Columns: [location, operator, plane_type] Index: []This does explicitly what
replace()does. Usingreplace()would be the preferred approach for what we have done here, because this subsetting approach does not allow for method chaining.
4.7.5 Exercises
These exercises use the PSID.csv data set
that was imported in the prior section.
Import the
PSID.csvdata set.Code
NAs for thekidsvariable.Display observations that contain missing values in the
Kidsvariable.