2 HTML
HTML is the language used to create webpages. When we copy and paste text from a webpage, we are interacting with just the result of the HTML code. The code tells our internet browsers how to display the content. When scraping, we interact directly with the HTML code, so we need to dive into this language and understand its syntax so that we can extract the information we want.
Webpages are designed for the user experience, not data collection, so it can get messy.
Take a look at this page: http://www.scrapethissite.com/pages/simple/
Imagine we want to scrape all of the country names off of the page. Which are the country names? How can we tell? We have background knowledge about most (hopefully) of the country names, so we can figure out that the country name are the first entry in each block.
If we want to build an automated scraper, how could it tell which pieces of text are country names? We identified them through a combination of background knowledge and pattern recognition, but our fixed code has neither of these.
Furthermore, a computer sees the HTML code, not the output that we are looking at, so we need to learn the code behind the page.
2.1 Elements
Elements are the fundamental unit in HTML. As a very simple example of an HTML element, take this code:
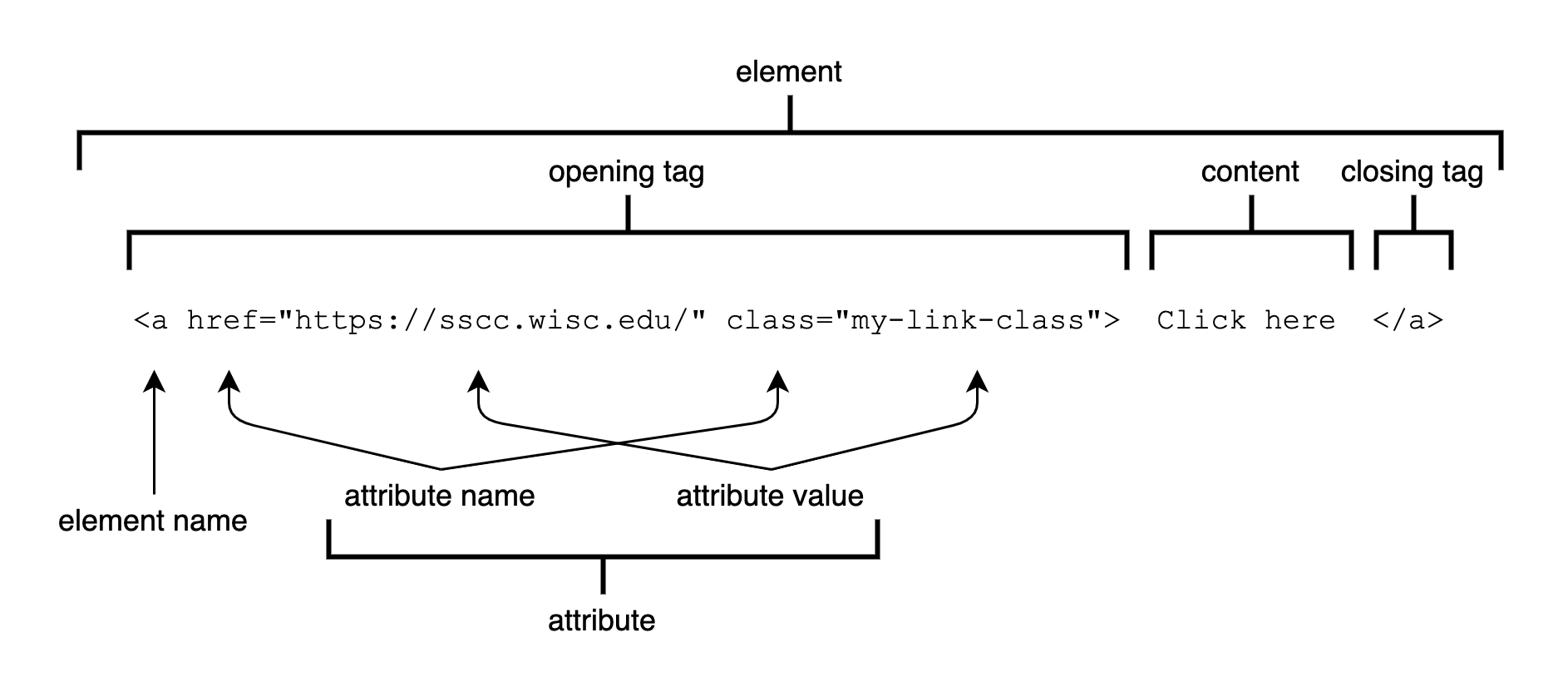
<a href="https://sscc.wisc.edu/" class="my-link-class"> Click here </a>which produces this link:
This line of code consists of one element. Elements are composed of several pieces:
Element names, which determine the output of the code, such as a link (
a), a paragraph (p), or a level-four header (h4)Opening tags and closing tags, which mark the start (
<a ... >) and the end of an element (</a>)Content, or text, which is outside angled brackets (
<>) and typically what we see displayed on the webpageAttributes, which determine additional properties of the elements, such as the link destination (
href) or an element’sclass, which is used for styling pages. Attributes follow aname=valueformat.
Common HTML elements include:
a, anchor, for linksbody, body of the documentbr, line breakdivandsection, sections of the documentem, italicized (emphasized) texth1,h2,h3,h4,h5, andh6, level-one through level-six headershtml, which defines the document as an HTML documentp, paragraph with line breaks before and afterspan, inline textstrong, bold texttable, table
Each element can take class and id attributes, and each element type can also take unique attributes. An id is simply a unique identifier for an element.
2.2 Relationships Between Elements
Now that we understand the basic syntax of an HTML element, let’s look at how multiple elements come together to form a webpage.
The webpage in this frame is a much-reduced version of the webpage we viewed earlier, http://www.scrapethissite.com/pages/simple/.
The HTML code that produced this page is below.
<html>
<body>
<h3>
Country Data
</h3>
<div class="col-md-4 country">
<h3 class="country-name">
Bulgaria
</h3>
<div class="country-info">
<strong>Capital:</strong> <span class="country-capital">Sofia</span><br>
<strong>Population:</strong> <span class="country-population">7148785</span><br>
<strong>Area (km<sup>2</sup>):</strong> <span class="country-area">110910.0</span><br>
</div>
</div>
<div class="col-md-4 country">
<h3 class="country-name">
Bahrain
</h3>
<div class="country-info">
<strong>Capital:</strong> <span class="country-capital">Manama</span><br>
<strong>Population:</strong> <span class="country-population">738004</span><br>
<strong>Area (km<sup>2</sup>):</strong> <span class="country-area">665.0</span><br>
</div>
</div>
<section id="footer">
<div class="container">
<div class="row">
Adapted from
<a href="https://scrapethissite.com/pages/simple/" class="data-attribution" target="_blank">Scrape This Site</a>
</div>
</div>
</section>
</body>
</html>We see some familiar elements and attributes in the code above, and some new ones too. Something else we see in this HTML code is that elements can appear not only before or after other elements, but also within other elements. This becomes clearer if we rearrange the code above into a tree diagram. We will just look at the element names to save space.
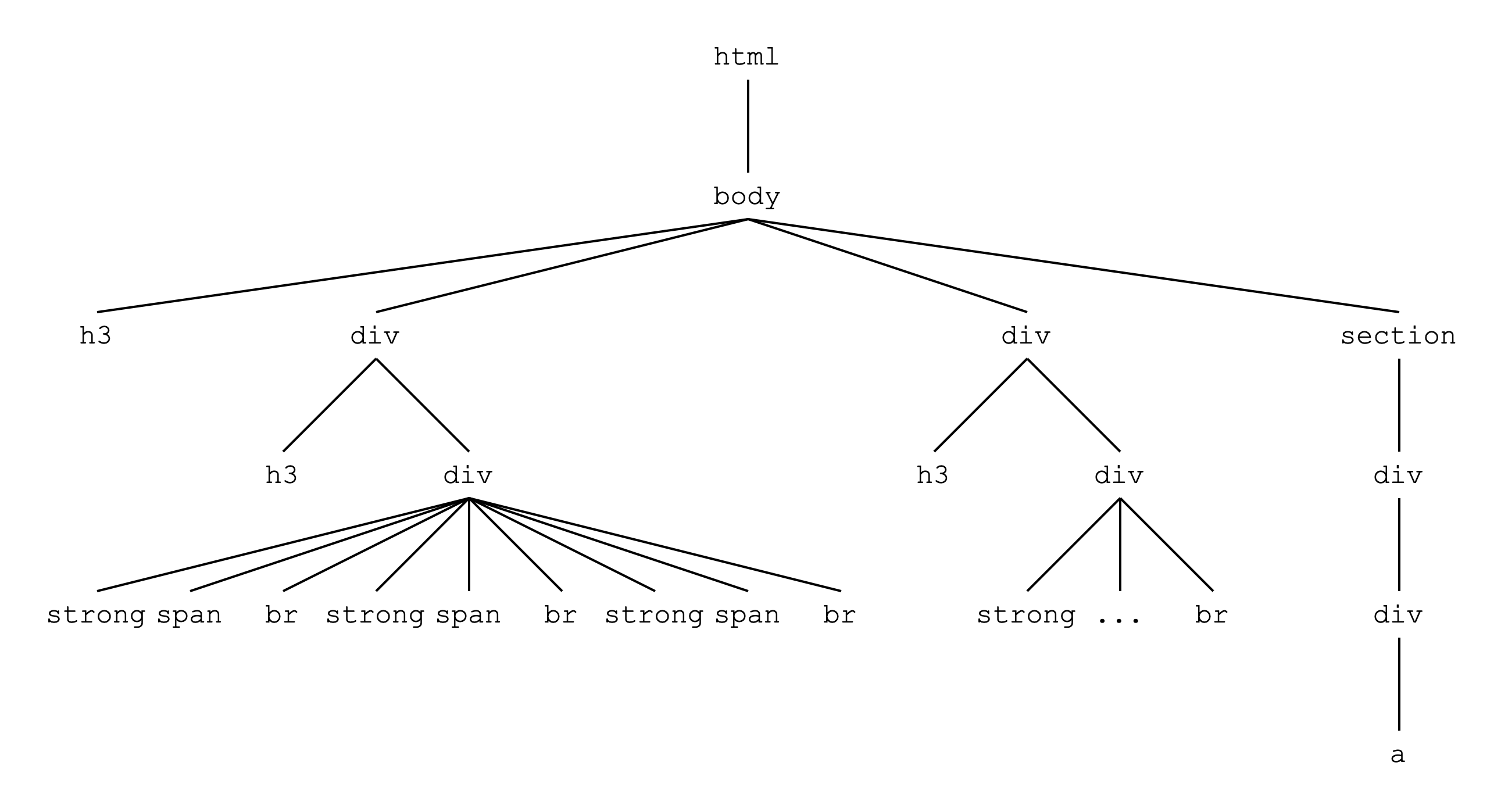
Note that the second div element contains all the same elements as the first div, but some elements have been abbreviated with ... for space reasons.
Elements can have one or more of several relationships with another element:
- Ancestors are elements that contain other elements
htmlis the ancestor of all other elementsbodyis the ancestor of all other elements excepthtmlbodyis the ancestor of threeh3elementssectionis the ancestor ofdiv,div, anda
- Descendants are elements contained within other elements
- All of the
strongelements are descendants ofdivelements, and also ofbody ais a descendant ofsection
- All of the
- Parents are direct ancestors of other elements: ancestors with no intervening generations
htmlis the parent ofbodybodyis the parent of oneh3element, twodivelements, and onesectionelement
- Children are direct descendants of other elements: descendants with no intervening generations
ais the child ofdiv- Two
h3elements are the children ofdivelements, and one is the child ofbody
- Siblings are elements that share the same parent
strong,span,br,strong,span,br,strong,span, andbrare siblingsahas no siblings- Each
h3has at least onedivsibling
2.3 Exercises
- Review the examples given for each type of relationship, and compare them to the HTML code printed at the beginning of Relationships Between Elements. Make sure you can see the relationships when the code is laid out in this way.
Use the code to answer the following questions, and verify your answers with the image.
How many ancestors does each of the three
h3elements have?How many descendants does each of the three
h3elements have?What is the parent of each
h3element?How many children does each
divhave?How many siblings does each
divhave?