3 CSS
We’ll use what are called “CSS selectors” to extract elements from a webpage. CSS stands for Cascading Style Sheets, and it takes the form of documents with rules that determine how a webpage is displayed. For example, the code below dictates that all h1 elements (level-one headers) should be blue and bold.
h1 {
color: blue;
font-weight: bold;
}CSS allows us to quickly and easily alter the appearance of a webpage just by changing one or two lines in our style sheet. If we change color: blue in the code above to color: red, all h1 elements will now appear red. Other common uses of CSS include specifying the width of the margins, or the colors of links before and after being clicked. Have you ever noticed that a page appears differently on your phone versus your computer, or that links appear blue before you click them but purple afterward? That’s CSS!
When web scraping, we are not interested in styling our webpages, so we do not need to pay attention to the settings in the curly braces ({}). Instead, we are most interested in the first line of the CSS code above: h1. This is an element selector, which finds all h1 elements and applies the following styles to them.
We can use CSS selectors to scrape information from webpages. If we want to pull out all of the h1 elements from a webpage, perhaps because they contain the information we want for our research, we can do that. We can also extract elements by other element components, such as class, id, or attribute, or by the context in which they appear, such as which elements they are nested within or follow.
3.1 Inspecting Elements
To get the information necessary for writing CSS selectors, we need to first view the page we want to scrape in our browser with the “Inspector”, which allows us to explore the HTML source code for the webpage.
How we open the Inspector varies by browser, and instructions for four major browsers are below.
| Browser | Open Inspector | Element Selection Button |
|---|---|---|
| Chrome |
Right-click on the page and select Inspect. Click on the Select an Element button. |
|
| Edge |
Right-click on the page and select Inspect. Click on the Select an Element button. |
|
| Firefox |
Right-click on the page and select Inspect. Click on the Pick an Element button. |
|
| Safari |
Right-click on the page and select Inspect Element. Click on the Start Element Selection button. |
|
Opening the Inspector and inspecting elements is accomplished in four steps. The “Open Inspector” column in the table above corresponds to Steps 1 and 2 below. Steps 3 and 4 show how we can take a closer look at elements in a webpage. These images were produced with Chrome on a Mac, and although each OS-browser combination will appear slightly differently, the steps remain the same.
Step 1. Right-click on the page and select Inspect. This opens up a split-window mode with our webpage and the Inspector.
Step 2. Click on the Select an Element button.
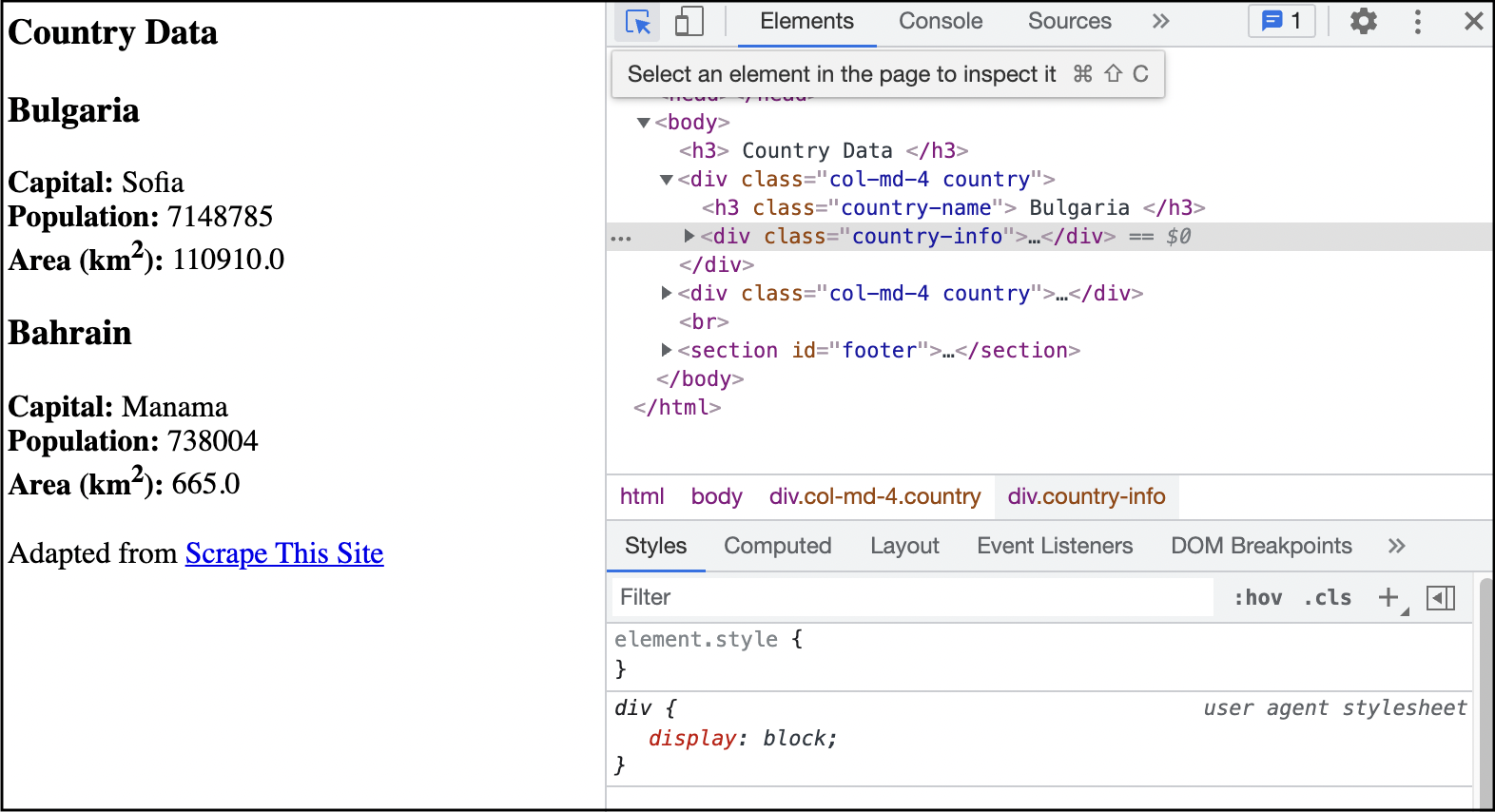
Step 3. Hover over an element on the webpage. A CSS selector for that element can be seen in the popup, but it does not necessarily uniquely identify the element.
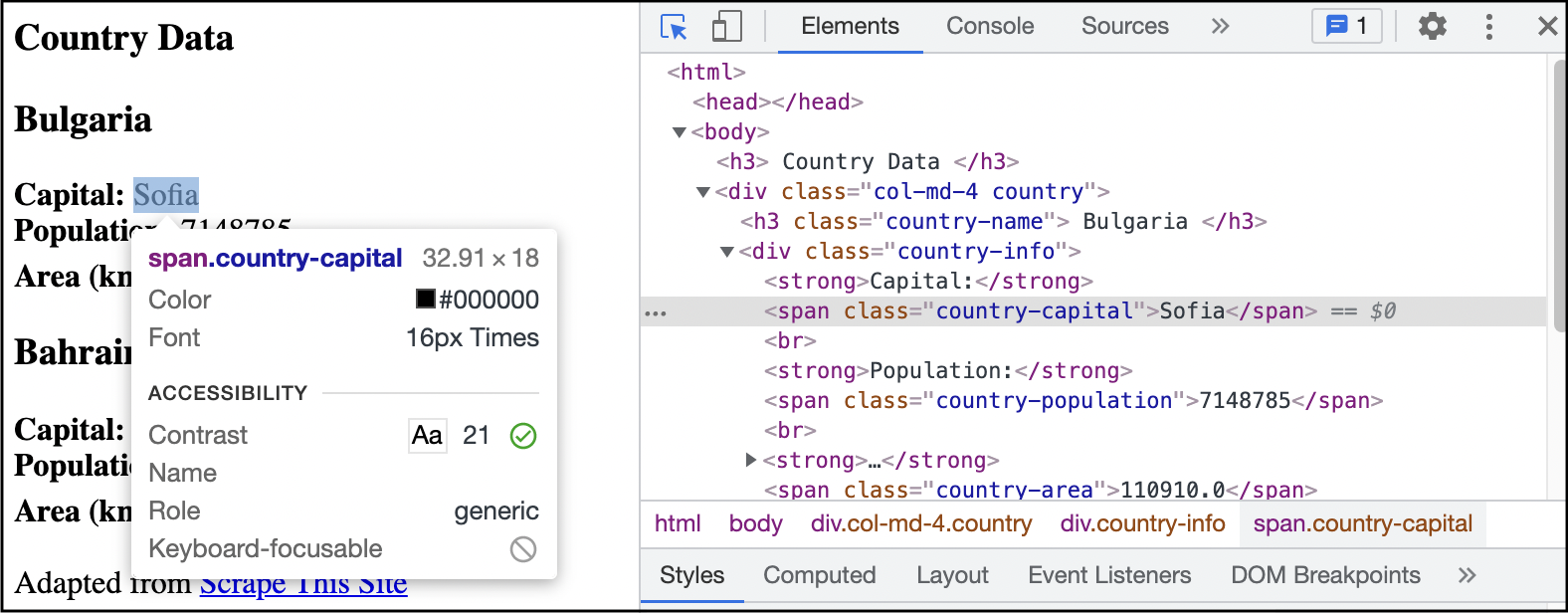
Step 4. Click on an element to find the HTML code producing that element. In addition to seeing information about the element, we also see important contextual information that can help us when writing CSS selectors.
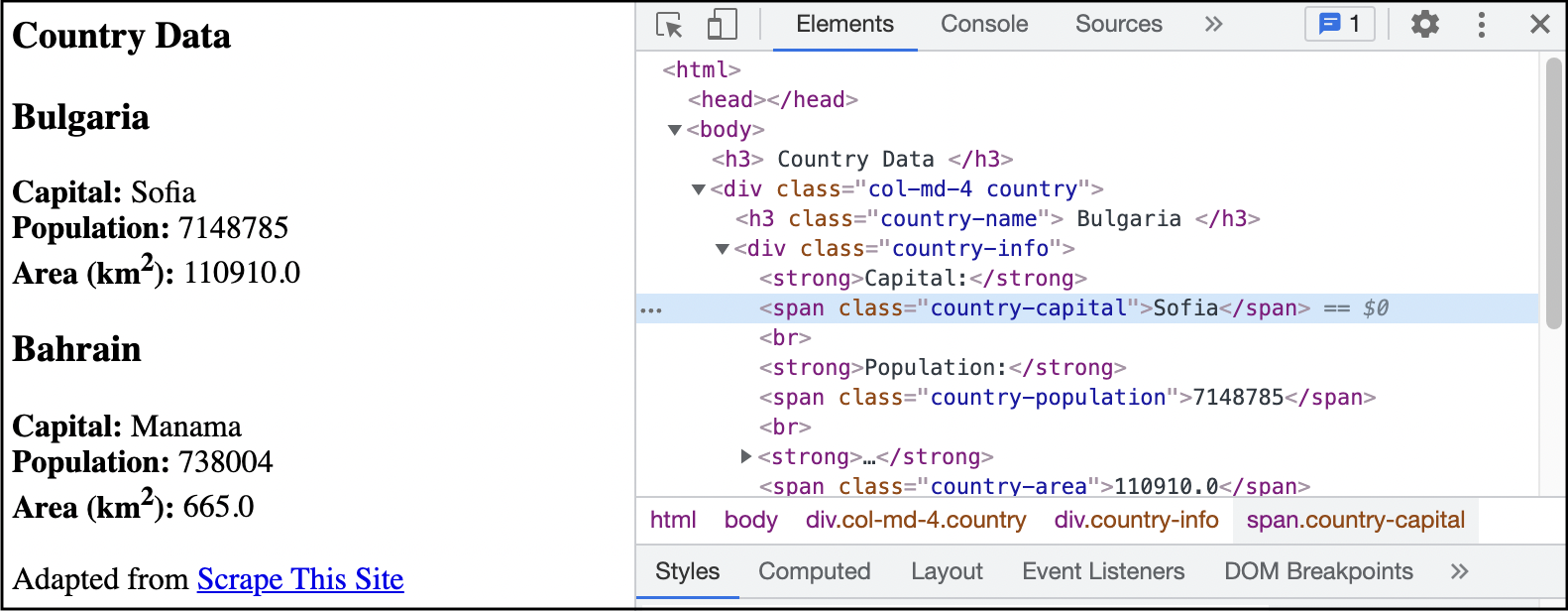
3.2 CSS Selectors
Now that we have an understanding of the basics of HTML elements and their relationships, and how to look up that information for a particular element, we are ready to select them with CSS.
CSS selectors provide a way to extract (filter) HTML elements by their element name, class, id, and other attributes, as well as by the relationships they share with other elements. Do you want all h1 elements? We can do that. Do you want all elements where class="special"? We can do that. Do you want all h3 elements that are the sibling immediately following p elements that are the children of h1 elements with class="special"? Yes, we can do that too.
For now, we will use CSS selectors to get elements and then extract their content (text). Later in Extract Data, we will use other functions to get attribute values and tables.
The table below contains a few of the CSS selectors you may find useful when web scraping.
- The “Selection Criteria” column contains the different ways we can select elements: by individual components or relationships, or by combining multiple components and relationships with Boolean operators (AND, OR, NOT).
- The “Operator” column gives the symbol or syntax we need to use.
- The “Example” column has example usage.
- The “Result of html_text2()”, gives the output of taking the values in “Example” and substituting them for
SELECTORin this code:countries |> html_elements("SELECTOR") |> html_text2()
where countries is the webpage we used in Relationships Between Elements, shown again in this frame:
For example, here is the example from the first line, where we select all h3 elements:
countries |> html_elements("h3") |> html_text2()## [1] "Country Data" "Bulgaria" "Bahrain"The output matches what we see in the final column.
| Selection Criteria | Operator | Example | Result of html_text2() |
|---|---|---|---|
| Element Type | (none) |
h3
|
Country Data, Bulgaria , Bahrain |
| Class |
.
|
.country-capital
|
Sofia , Manama |
| ID |
#
|
#footer
|
Adapted from Scrape This Site |
| Attribute |
[]
|
[href]
|
Scrape This Site |
| Attribute Starting with Value |
[ ^=' ']
|
[href^='https']
|
Scrape This Site |
| Attribute Ending with Value |
[ $=' ']
|
[target$='ank']
|
Scrape This Site |
| Attribute Containing Value |
[ *=' ']
|
[class*='attrib']
|
Scrape This Site |
| Anything/Everything |
*
|
*
|
(all of the elements) |
| Descendants | (space) |
div h3
|
Bulgaria, Bahrain |
| Children |
>
|
div>.country-area
|
110910.0, 665.0 |
| Subsequent Sibling (After) |
~
|
span~span
|
7148785 , 110910.0, 738004 , 665.0 |
| Next Sibling (Immediately After) |
+
|
br+strong
|
Population:, Area (km2):, Population:, Area (km2): |
| Logical AND | (no space) |
h3.country-name
|
Bulgaria, Bahrain |
| Logical OR |
,
|
h3 , .country-area
|
Country Data, Bulgaria , 110910.0 , Bahrain , 665.0 |
| Logical NOT |
:not()
|
span:not(.country-area)
|
Sofia , 7148785, Manama , 738004 |
Note that we can select elements by relationship in only one direction. We can select descendants, children, and later siblings, but not ancestors, parents, or earlier siblings. This is because HTML documents are processed from top to bottom, so it is not possible to go the other way, either up or backward in our HTML tree. We can find an element and pick its children, but we cannot find those children and then reverse course to pick their parent.
This table is far from exhaustive. For more on CSS selectors, see this extensive table and this technical report.
3.3 Exercises
- Play this game to master the basics of CSS selectors.
For 2-8, use the countries example page for the following questions, which you can download with this code:
library(polite)
library(rvest)
countries <-
bow("https://sscc.wisc.edu/sscc/pubs/data/webscraping-r/countries_excerpt.html") |>
scrape()You will also need to visit the page in your browser and inspect it to view the code.
Select all
divelements.Select all elements where
class="country-population".Select all elements with a
classattribute.Select all elements that are children of a
bodyelement.Write a selector to get output of
"2" "2".We already saw two ways to get just the country names “Bulgaria” and “Bahrain”. Find at least two more ways to get them.
Select anything (
*) immediately after anh3element.