8 No Outlier Effects
What this assumption means: Our statistical model accurately represents the relationships in the data.
Why it matters: Outliers, which are observations whose values greatly differ from those of other observations, sometimes have disproportionately large influence on the predicted values and/or model parameter estimates.
How to diagnose violations: Large values of DFFITS and/or DFBETAS.
How to address it: Examine influential observations and investigate why they are outliers. Add predictors to the model.
8.1 Example Model
If you have not already done so, download the example dataset, read about its variables, and import the dataset into Stata.
Then, use the code below to fit this page’s example model.
use acs2019sample, clear
reg income c.age##i.sex hours_worked weeks_worked Source | SS df MS Number of obs = 2,761
-------------+---------------------------------- F(5, 2755) = 107.80
Model | 1.4368e+12 5 2.8736e+11 Prob > F = 0.0000
Residual | 7.3442e+12 2,755 2.6658e+09 R-squared = 0.1636
-------------+---------------------------------- Adj R-squared = 0.1621
Total | 8.7810e+12 2,760 3.1815e+09 Root MSE = 51631
------------------------------------------------------------------------------
income | Coefficient Std. err. t P>|t| [95% conf. interval]
-------------+----------------------------------------------------------------
age | 879.1899 83.08639 10.58 0.000 716.272 1042.108
|
sex |
Female | 4155.126 5802.984 0.72 0.474 -7223.514 15533.76
|
sex#c.age |
Female | -339.2445 123.3531 -2.75 0.006 -581.1184 -97.37052
|
hours_worked | 1003.744 79.44316 12.63 0.000 847.9695 1159.518
weeks_worked | 409.3063 80.37874 5.09 0.000 251.6977 566.915
_cons | -40452.08 5337.019 -7.58 0.000 -50917.05 -29987.12
------------------------------------------------------------------------------8.2 Statistical Tests
Outliers can be classified into three types:
- Extreme values
- Leverage
- Influence, which can be divided into two types:
- Influence on predicted values
- Influence on parameter estimates
8.2.1 Extreme Values
Extreme values can be identified as points with high residuals. Since residuals are on the scale of the predicted values, we standardize residuals by dividing them by their standard deviation.
Externally studentized residuals use a separate residual variance for each case by excluding that case from the variance calculation. Internal studentization calculates a single variance.
The distribution of studentized residuals follows the familiar Student’s t-distribution, so we can consider values outside the range [-2, 2] as potential outliers.
We will use externally studentized residuals.
Use predict newvar, rstudent to calculate the studentized residuals, and add an indicator whether the value is outside the range [-2, 2].
predict res_stud, rstudent
gen res_stud_large = ( res_stud < -2 | res_stud > 2 ) & res_stud < .(2,239 missing values generated)8.2.2 Leverage
Leverage is a measure of the distance between individual values of a predictor and other values of the predictor. In other words, a point with high leverage has an x-value far away from the other x-values. Points with high leverage have the potential to influence our model estimates.
Leverage values range from 0 to 1. Various cutoffs exist for determining what is considered a large value. As an example, we can consider an observation as having large leverage if6
\(Leverage_i > \frac {2k} {n}\)
where k is the number of predictors (including the intercept) and n is the sample size.
Calculate leverage with predict newvar, leverage and the cutoff from the number of predictors and observations. Then, flag cases with high leverage.
predict lev, leverage
gen lev_cutoff = 2 * (e(df_m) + 1) / e(N)
gen lev_large = (lev > lev_cutoff) & lev < .(2,239 missing values generated)8.2.3 Influence
Leverage and residuals are fairly abstract outlier metrics, and we are often more interested in the substantive impact of an observation in our model, or influence.
Influence is a measure of how much an observation affects our model estimates. If an observation with large influence were removed from the dataset, we would expect a large change in the predictive equation.
Two measures are discussed below, and they both compare models with and without a given observation. DFFITS is a measure of the change in predicted values, while DFBETAS is a measure of the change in each of the model parameter estimates.
8.2.3.1 Influence on Prediction
DFFITS is a standardized measure of how much the prediction for a given observation would change if it were deleted from the model. Each observation’s DFFITS is standardized by the standard deviation of fit at that point. It can be formulated as the product of an observation’s studentized residual, \(t_i\), and its leverage, \(h_i\):
\(DFFITS_i = t_i \times \sqrt{ \frac { h_i } { 1 - h_i } }\)
This means that a point with a large absolute residual and leverage will have a large DFFITS value.
A cutoff for DFFITS is
\(| DFFITS_i | > 2 \times \sqrt{ \frac {k} {n} }\)
where \(k\) is the number of predictors and \(n\) is the number of observations.
Calculate DFFITS with predict newvar, dfits, and add an indicator whether a given observations DFFITS value is beyond the cutoff.
predict dffits, dfits
gen dffits_cutoff = 2 * sqrt( (e(df_m) + 1) / e(N) )
gen dffits_large = (abs(dffits) > dffits_cutoff) & dffits < .(2,239 missing values generated)8.2.3.2 Influence on Parameter Estimates
DFBETAS are standardized differences between regression coefficients in a model with a given observation, and a model without that observation. DFBETAS are standardized by the standard error of the coefficient. A model, then, has \(n \times k\) DFBETAS, one for each combination of observations and predictors.
A cutoff for what is considered a large DFBETAS value is
\(| DFBETAS_i | > \frac {2} {\sqrt{n}}\)
where \(n\) is the number of observations.
Adding the DFBETAS to our dataset is a little more involved because dfbeta returns multiple columns, so we have to loop through these columns to create an indicator for each one.
// save dfbetas values and prefix with "dfb_"
dfbeta, stub(dfb_)
// add indicators for each dfbetas variable and suffix with "_large"
foreach dfb of varlist dfb_* {
gen `dfb'_large = ( abs(`dfb') > 2/sqrt(e(N)) ) & `dfb' < .
}Generating DFBETA variables ...
(2,239 missing values generated)
dfb_1: DFBETA age
(2,239 missing values generated)
dfb_2: DFBETA 2.sex
(2,239 missing values generated)
dfb_3: DFBETA 2.sex#c.age
(2,239 missing values generated)
dfb_4: DFBETA hours_worked
(2,239 missing values generated)
dfb_5: DFBETA weeks_worked8.3 Visual Tests
We can plot DFFITS and DFBETAS by their index, and color-code them if they fall outside a cutoff point. When we look at these plots, we ask ourselves, does any individual point or group of points stand out? We expect that some points will be outside the cutoff. What we are looking for are any especially noteworthy points.
Plot the DFFITS:
// add index number
gen obs_number = _n
twoway (scatter dffits obs_number if dffits_large==0) ///
(scatter dffits obs_number if dffits_large==1, mcolor(red)), ///
legend(off) ///
yline(`=2 * sqrt( (e(df_m) + 1) / e(N) )', lcolor(red)) ///
yline(`=-2 * sqrt( (e(df_m) + 1) / e(N) )', lcolor(red))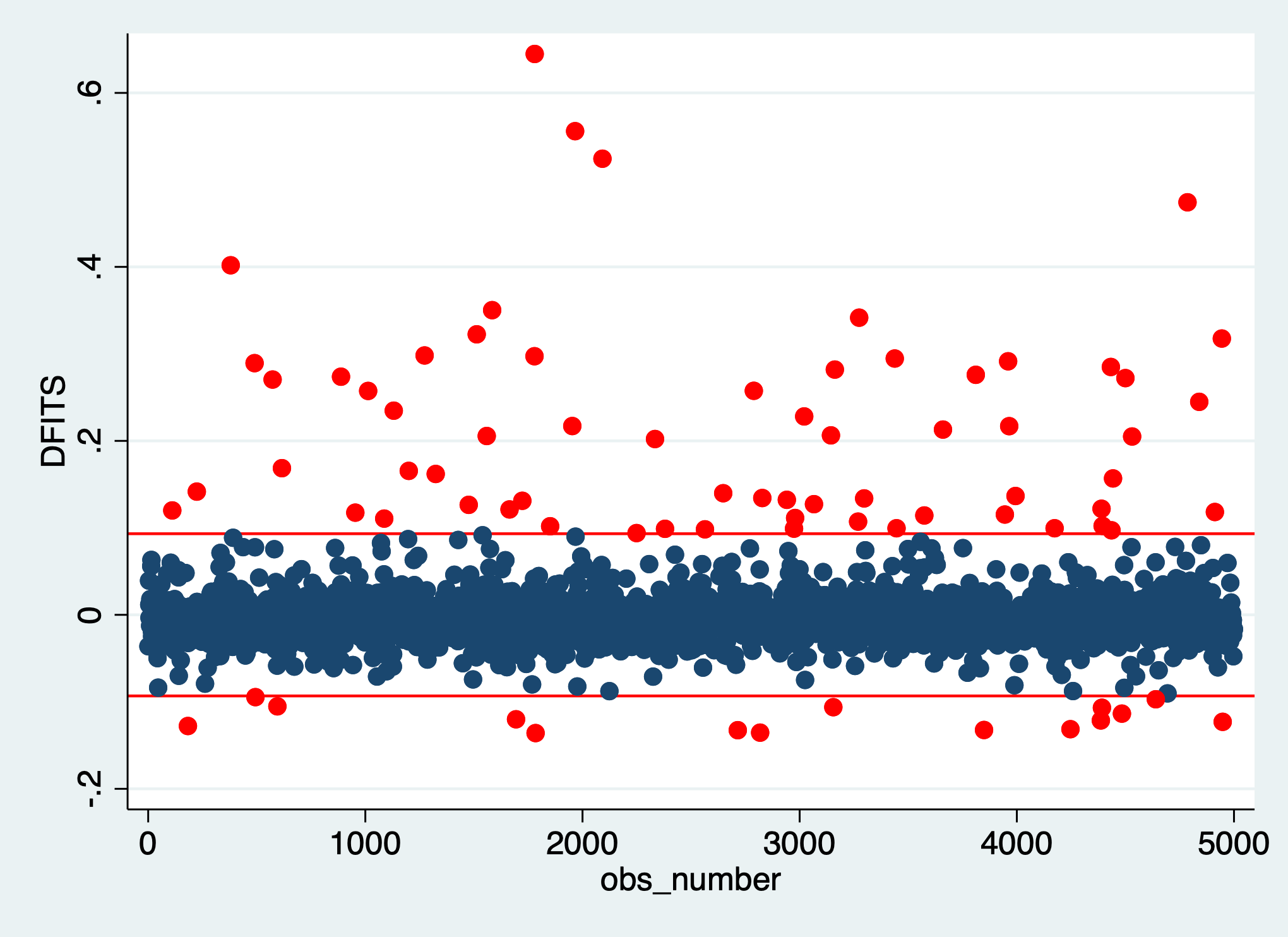
A few points stand out in this plot. We should look into the five points with DFFITS values over 0.4. (Not because 0.4 is a special number, just because it helps us identify those five points.)
Plot the DFBETAS:
// save copy of dataset so we can undo the reshape
preserve
// print key for interpreting coefficient numbers in plot
describe dfb_*
// rename to make reshape easier, then reshape
rename (dfb_*_large) (dfb_large_*)
reshape long dfb_ dfb_large_, i(obs_number) j(coef)
twoway (scatter dfb_ obs_number if dfb_large_==0, msize(1pt)) ///
(scatter dfb_ obs_number if dfb_large_==1, mcolor(red) msize(1pt)), ///
by(coef, legend(off)) ///
yline(`=2/sqrt( e(N)) )', lcolor(red)) ///
yline(`=-2/sqrt( e(N)) )', lcolor(red)) ///
ylabel(#5)
// reload data from before reshape
restoreVariable Storage Display Value
name type format label Variable label
-----------------------------------------------------------------------------------------------------
dfb_1 float %9.0g DFBETA, age
dfb_2 float %9.0g DFBETA, 2.sex
dfb_3 float %9.0g DFBETA, 2.sex#c.age
dfb_4 float %9.0g DFBETA, hours_worked
dfb_5 float %9.0g DFBETA, weeks_worked
dfb_1_large float %9.0g
dfb_2_large float %9.0g
dfb_3_large float %9.0g
dfb_4_large float %9.0g
dfb_5_large float %9.0g 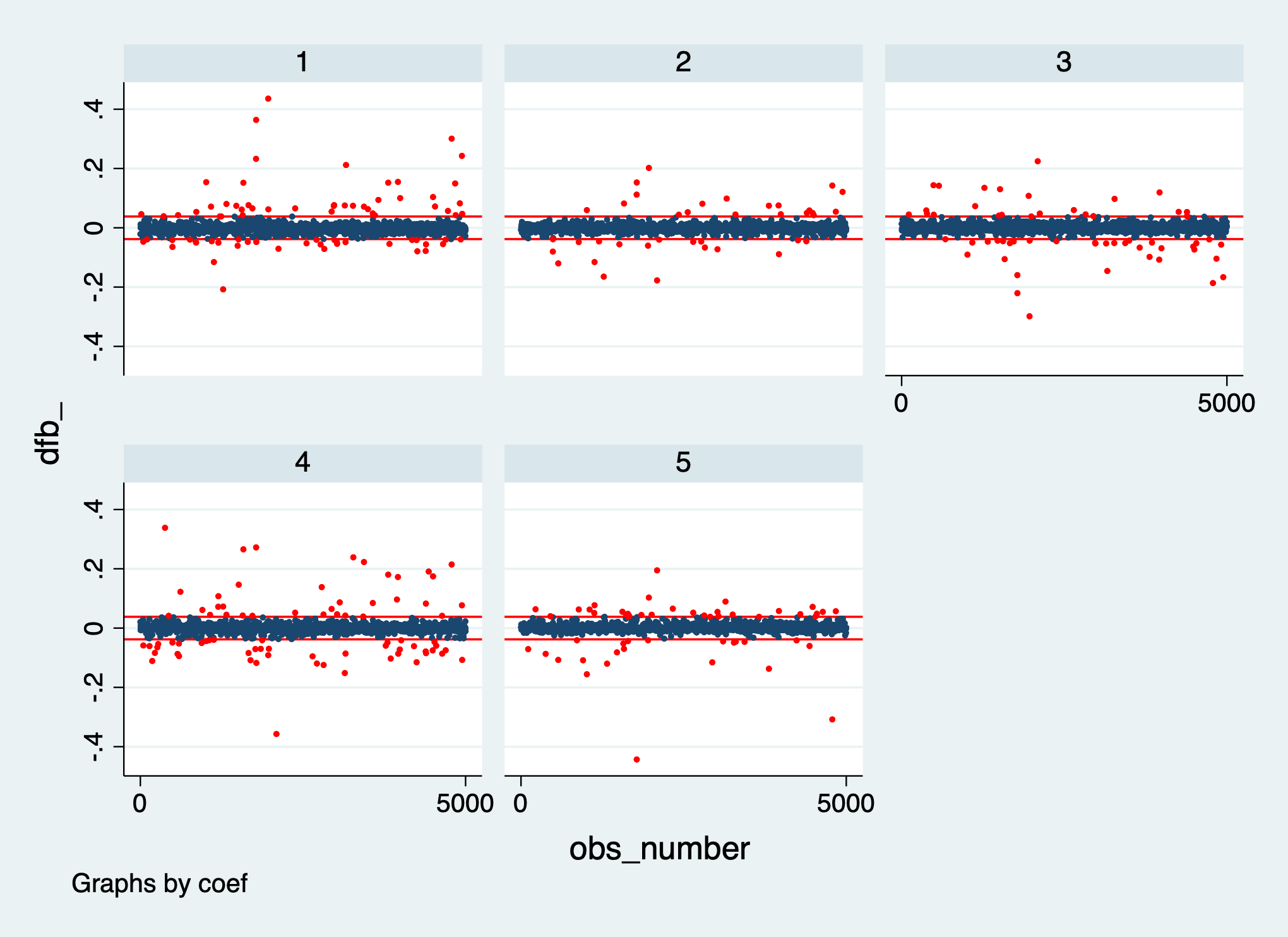
Several points stand out in the plots for age, the interaction of age and sex, hours_worked, and weeks_worked. These plots have a few large positive and/or negative DFBETAS around observations 2000 and 5000.
To investigate any points we identified in the plot, we can take a subset of our data, filtering observations by any cutoffs we decided on after looking at the plots:
gen influential_obs = 0
replace influential_obs = 1 if (dffits > .4 & dffits < .)
forvalues i=1/`e(df_m)' {
replace influential_obs = 1 if (dfb_`i' > .25 & dfb_`i' < .)
}
keep if influential_obsThis subset has only six observations, meaning these points were responsible for influencing the fit and a number of parameters. Of course, we could adjust our cutoffs to identify even more observations we should investigate, but this is a good place to start.
8.4 Corrective Actions
First, investigate why some observations were identified as outliers. Here, subject matter knowledge is crucial. Outlier detection methods simply tell us which observations are different or influential, and our task is to figure out why certain observations are outliers.7
Before you investigate individual observations in-depth, revisit the other assumptions. A violation of another assumption can have the effect that we identify many observations as outliers.
- Examine the dataset.
- Read the codebook and any other associated documentation for the dataset.
- Consider how the data was collected (oral interviews, selected-response surveys, open-response surveys, web scraping, government records, etc.).
- Consider how the population of generalization is defined, and how this sample was drawn.
- For observations identified as having outlying values, check whether they differ from the other observations with respect to other variables.
Then, based on your findings, decide what to do with the outliers.8 Always make a note in your write-up how you handled outliers.
- If you found a pattern in the observations with outliers, modify the model (add, drop, or transform variables). Examples:
- Individuals who reported extremely high values of income also reported working over ninety hours per week, and hours worked was not included as a predictor.
- Individuals who reported extremely long commute times also reported they take ferryboats to work, and mode of transportation was not included in the model.
- If you know (with relative certainty) what the value should be, correct it. Examples:
- Data entry errors like misplaced decimal points (GPA of 32.6 instead of 3.26).
- Incorrect scale of variable (monthly rather than yearly income).
- If the observation is not from the target population, either remove it or adjust your generalizations. Examples:
- Study on trends in teacher use of technology in 2000-2020 includes period of fully-remote learning during pandemic.
- Data used to answer questions about workplace interactions includes individuals working from home.
- If the value reflects construct-irrelevant variance, remove it. Examples:
- An extremely long reaction time in a laboratory task after a participant was distracted by a noise next door.
- Bias or differential item functioning in surveys or assessments.
- If the distribution of values does not match the distribution assumed by the model, modify the model (add, drop, or transform variables) or fit a generalized linear model. Examples:
- Income follows a skewed distribution so a model assuming normality would identify legitimate values as outliers.
- An unmodeled categorical variable causes the outcome (and residuals) to have a bimodal distribution.
Additional recommendations apply to situations using structural equation modeling or multilevel modeling.9
After you have applied any corrections or changed your model in any way, you must re-check this assumption and all of the other assumptions.
The cutoff values in this chapter are based on those found in, Belsley, D. A., Kuh, E., and Welsch, R. E. (1980). Regression Diagnostics: Identifying influential data and sources of collinearity. Wiley. https://doi.org/10.1002/0471725153
For a discussion of alternative cutoffs, see chapter 4 of, Fox, J. D. (2020). Regression diagnostics: An introduction (2nd ed.). SAGE. https://doi.org/10.4135/9781071878651↩︎For examples and discussion, see, Bollen, K. A., & Jackman, R. W. (1985). Regression diagnostics: An expository treatment of outliers and influential cases. Sociological Methods & Research, 13(4), 510-542. https://doi.org/10.1177/0049124185013004004↩︎
For more cases and examples, see chapter seven in, Osborne, J. (2013). Best practices in data cleaning: A complete guide to everything you need to do before and after collecting your data. Sage. https://doi.org/10.4135/9781452269948↩︎
Aguinis, H., Gottfredson, R. K., & Joo, H. (2013). Best-practice recommendations for defining, identifying, and handling outliers. Organizational Research Methods, 16(2), 270-301. http://doi.org/10.1177/1094428112470848↩︎