display "Hello World!"Hello World!Ever needed to do the same thing to ten different variables and wished that you didn’t have to write it out ten times? If so, then this article is for you. If not, someday you will, so you might as well keep reading anyway.
This article will teach you how to write loops in Stata, including an introduction to the Stata macros that make loops work. We’ll give many examples of ways you can use loops, such as looping over variables, looping over files, and looping over values. The primary audience people who are early in their Stata careers with no other programming experience who are looking to go beyond linear do files for the first time. More experienced programmers may find they can skip a lot of the explanations.
A macro is a box you can put some text in. You can then use the text in later commands. We’ll soon learn how to run code repeatedly with different text in the macro box each time, but we’ll start by learning to use macros all by themselves.
The easiest way to see a macro at work is with the display command. Whatever you type after the word display will be displayed on the screen–it’s the Stata equivalent of a print function. If the content is in quotes, it will be displayed as-is:
display "Hello World!"Hello World!Anything that’s not in quotes will be treated as a mathematical expression, evaluated, and then display will show the result:
display "2 + 2 = " 2+22 + 2 = 4This allows you to use Stata as an convenient hand calculator. Note that you can abbreviate display to just di.
Stata actually has two kinds of macros: local and global. We’ll discuss the differences between them later (if you’ve run into local and global variables in some other programming language, Stata works the same way) but for now just know that you usually want to use local macros and those are the kind we’ll focus on. You define a local macro with the local command, followed by the name of the macro and its contents:
local x 1This defines a local macro called x and stores the character 1 in it.
To use a local macro, you put its name in a particular combination of quotes: `x'. The first character is the backtick, or left single quote, which is usually found in the upper-left corner of the keyboard along with the tilde. The last character is the right single quote, found on the right side of the keyboard along with the double quote. You can use macros in any Stata command, including display:
display `x'1When you enter a Stata command, the first thing that happens is the macro processor examines it for macros. If it finds one, it replaces the name of the macro with its content. Only then does it pass the command to Stata proper. This makes macros very flexible: you can use them absolutely anywhere because Stata proper doesn’t even know they were there. For example:
local x 2+2
display `x'4Here, the macro x contained a mathematical expression: a small bit of actual executable code. The display command then calculated the result. You can see the original content of the macro by displaying it as a string:
display "`x'"2+2What follows display in that command can be hard to read: the characters are double quote, left single quote (or backtick), x, right single quote, double quote. Unfortunately macros in strings are fairly common, so get used to lots of quotes.
You can tell the local command to store the result of an expression by putting in an equals sign:
local x = 2+2
display "`x'"4With an equals sign in the macro definition, Stata calculated 2+2 and then stored the result, 4, in the local macro x. That’s why you get 4 even when you tell display to print x inside a string: now x actually contains 4, not 2+2.
The macro processor is also capable of evaluating mathematical expressions. If you start an expression with `= and end it with ', the macro processor will replace the expression with its result before the command is executed:
display "`= 2+2 '"4Any time you need a number in your Stata code, you can instead write a macro expression that calculates the number for you.
You can also use macros inside macro expressions, or macro names:
display "`= `x' + 1'"5local french_1 un
local french_2 deux
local french_3 trois
local french_4 quatre
local french_5 cinq
display "`french_`x''"quatreDefine a local macro called pi containing as many digits of pi as you can remember. Then use it to display the area of a circle with a radius of 10 centimeters. Your answer should be a sentence that contains the number and specifies the units. (Hint: the area of a circle is pi * radius^2.)
local pi 3.1415927
display "The area of a circle with radius 10cm is `=`pi'*10^2'cm^2."The area of a circle with radius 10cm is 314.15927cm^2.Before we move on to loops, let’s look at some other ways you might use macros.
When you run a command like sum, returned results in the r() vector, like r(mean), are available as local macros as well as values that can be used in mathematical expressions.
clear
sysuse auto
sum mpg
display "The mean of mpg is `r(mean)'"(1978 automobile data)
Variable | Obs Mean Std. dev. Min Max
-------------+---------------------------------------------------------
mpg | 74 21.2973 5.785503 12 41
The mean of mpg is 21.2972972972973When you run a regression, results in the e() vector are also defined as local macros. However, coefficients in the form _b[] are not. They are only defined as values for use in mathematical expressions. But that’s not a problem–just use a macro expression:
reg mpg weight
display "The r-squared is `e(r2)'"
display "The coefficient for weight is `=_b[weight]'"
Source | SS df MS Number of obs = 74
-------------+---------------------------------- F(1, 72) = 134.62
Model | 1591.9902 1 1591.9902 Prob > F = 0.0000
Residual | 851.469256 72 11.8259619 R-squared = 0.6515
-------------+---------------------------------- Adj R-squared = 0.6467
Total | 2443.45946 73 33.4720474 Root MSE = 3.4389
------------------------------------------------------------------------------
mpg | Coefficient Std. err. t P>|t| [95% conf. interval]
-------------+----------------------------------------------------------------
-.0060087 .0005179 -11.60 0.000 -.0070411 -.0049763
_cons | 39.44028 1.614003 24.44 0.000 36.22283 42.65774
------------------------------------------------------------------------------
The r-squared is .6515312529087511
The coefficient for weight is -.0060086868119993You can control the format of the numbers using a macro function called display. It has the same name as the display command because they work the same way. To display a number in a particular format, put the format before the number in the display command:
display %5.3f e(r2)0.652The % signifies that what follows is a format. The 5 sets the total number of characters, and the .3 sets the number of digits to display after the decimal point. Note that if the number of characters is bigger than the number to display, spaces will be added before the number (i.e. the number will be right-justified). The f means to use fixed format, which gives you more control. fc would add commas to make big numbers more readable.
To use a macro function in a macro definition, you use the local command but with a colon after the name of the macro to be defined, followed by the name of the function. The result of the function will then be stored in the macro.
The display macro function acts just like the display command, except that the result is put in a macro for later use:
local r2: display %5.3f e(r2)
scatter mpg weight || lfit mpg weight, note("R-squared=`r2'")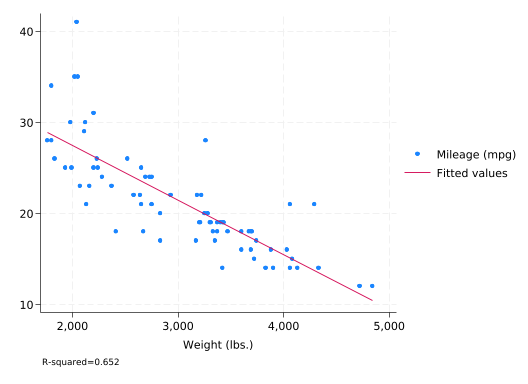
Display the text “The correlation between weight and mpg is” followed by the actual correlation to two decimal places. Hint: you can calculate the correlation using the correlate command (or just cor), and see the names of the results it returns by running return list.
cor mpg weight(obs=74)
| mpg weight
-------------+------------------
mpg | 1.0000
weight | -0.8072 1.0000
return list
scalars:
r(N) = 74
r(rho) = -.807174858942442
matrices:
r(C) : 2 x 2local cor: display %5.2f r(rho)
display "The correlation between mpg and weight is `cor'"The correlation between mpg and weight is -0.81Suppose you wanted to run a bunch of regressions and they all had the same set of control variables. You can make that easier by storing the list of control variables in a macro:
local controls weight i.foreign
reg mpg displacement `controls'
Source | SS df MS Number of obs = 74
-------------+---------------------------------- F(3, 70) = 45.88
Model | 1619.71935 3 539.906448 Prob > F = 0.0000
Residual | 823.740114 70 11.7677159 R-squared = 0.6629
-------------+---------------------------------- Adj R-squared = 0.6484
Total | 2443.45946 73 33.4720474 Root MSE = 3.4304
------------------------------------------------------------------------------
mpg | Coefficient Std. err. t P>|t| [95% conf. interval]
-------------+----------------------------------------------------------------
displacement | .0019286 .0100701 0.19 0.849 -.0181556 .0220129
weight | -.0067745 .0011665 -5.81 0.000 -.0091011 -.0044479
|
foreign |
Foreign | -1.600631 1.113648 -1.44 0.155 -3.821732 .6204699
_cons | 41.84795 2.350704 17.80 0.000 37.15962 46.53628
------------------------------------------------------------------------------ologit rep78 gear_ratio `controls'
Iteration 0: Log likelihood = -93.692061
Iteration 1: Log likelihood = -79.459332
Iteration 2: Log likelihood = -78.730702
Iteration 3: Log likelihood = -78.724893
Iteration 4: Log likelihood = -78.72489
Ordered logistic regression Number of obs = 69
LR chi2(3) = 29.93
Prob > chi2 = 0.0000
Log likelihood = -78.72489 Pseudo R2 = 0.1597
------------------------------------------------------------------------------
rep78 | Coefficient Std. err. z P>|z| [95% conf. interval]
-------------+----------------------------------------------------------------
gear_ratio | -.7164374 .9438132 -0.76 0.448 -2.566277 1.133403
weight | -.0001694 .0005185 -0.33 0.744 -.0011856 .0008467
|
foreign |
Foreign | 3.349109 .8769805 3.82 0.000 1.630259 5.067959
-------------+----------------------------------------------------------------
/cut1 | -5.720909 4.025293 -13.61034 2.168519
/cut2 | -3.930756 3.983823 -11.73891 3.877394
/cut3 | -1.330952 3.97307 -9.118027 6.456122
/cut4 | .7080591 3.968134 -7.06934 8.485458
------------------------------------------------------------------------------Saving a little typing is the least important benefit of doing so. It makes your code for each model easier to read in that it lets you focus on what’s important (there are control variables) rather than details (what exactly the control variables are, though of course you can easily find out by looking at the macro definition). It reduces the opportunities for error, like leaving out a control variable from a model. It also makes it easy to change your control variables: just change the macro definition and run the models again.
Note that putting a long list of predictors in a macro makes it easy to run a “kitchen sink” model, where you include every predictor you think might possibly be relevant. It does not make running a kitchen sink model a good idea.
Now that we’ve got some practice with local macros, we’ll talk about what it means that they are local. We’ll also talk about the alternative, global macros.
A local macro has a specific context and only exists in that context. Usually that context is a do file. If you define a macro in a do file, then try to use it after the do file is running, you’ll find that it doesn’t exist.
If you’ve been doing these examples interactively, open the do file editor, define a macro y there, and run the do file.
local y 3Now go back to the main Stata window and try to use the macro y in an interactive command:
display "Macro y contains `y'"Macro y contains What happened here? Because y is a local macro defined in a do file, it only exists while the do file is running. As soon as the do file ended, it disappeared. Using a macro that does not exist is not an error as far as Stata is concerned. The macro processor recognizes you’re using a macro called y, but sees it has no content for a macro called y. So it replaces y with nothing. Thus it’s the same as using a macro that was never defined at all:
display "Macro z contains `z'"Macro z contains Of course it’s not likely you intended to use a macro that does not exist. One common cause is typos. Be very careful about typing macro names. If you’re lucky, a typo in a macro name will leave you with code that crashes, making it obvious there’s an error (if not what the error is). Code that runs and gives you plausible-looking results that are not the results you wanted is much more dangerous.
The other common cause is running part of a do file. Copy the display command into your do file. If you run the entire do file it should work now:
local y 3
display "Macro y contains `y'"Macro y contains 3But if you first select and run the first line, then select and run the second line, you’ll again get nothing for macro y. That’s because it disappeared as soon as the first line finished running, and thus no longer exists when you run the second line. Once you start writing code that uses macros you need to either run entire do files or be careful to include the definitions of any macros you use in the code you run.
A global macro is very similar to a local macro, but it does not belong to a specific context and does not go away until you close Stata. You define them with the global command:
global x 1However, you use them by putting a dollar sign in front of the name:
display $x1Global macros may seem easier to use, but they’re subtly dangerous. Suppose you’re working on two projects, each in a different directory. You decide to put the appropriate directory name in a global macro (a practice the SSCC’s statistical consultants see fairly regularly). So a do file for the first project starts with:
global dir c:\users\bbadger\project1While a do file for the second project starts with:
global dir c:\users\bbadger\project2One day you work on project 1 for a while, then want to switch over to project 2. So you open a project 2 do file, jump to the middle of the file, and select and run a part of the file containing:
save $dir/dataset, replaceWhere will the resulting data set go? The global macro dir was set to c:\users\bbadger\project1 while you were working on project 1, and since you didn’t run the project 2 do file from the beginning, it was never changed. Thus dataset will be saved in c:\users\bbadger\project1 even though it belongs to project 2. Hopefully project 1 didn’t also have a file called dataset, because if it did it’s now gone.
The root cause of the problem is that different contexts can use the same macro names, and mixing them up can be disastrous. That’s why local macros are tied to a specific context, and using them avoids this problem completely. This is critical for the developers of Stata: most Stata commands are actually do files, they use a lot of macros, and it would cause major problems if they could overwrite your macros. Thus the developers always use local macros, and local macros get more attention as a result. Most relevantly, Stata loops were built around using local macros.
If you make the directory of the project you’re working on the working directory and use all relative paths inside your do files, you don’t need to use anything like $dir. See the discussion of file systems in Data Wrangling in Stata.
Now that you’re comfortable using macros, you’re ready to learn how to write loops. We’ll start with foreach loops.
A foreach loops executes a block of code once “for each” item in a list. The item being worked on is placed in a local macro. Consider the following simple loop:
foreach color in red blue green {
display "`color'"
}red
blue
greenWhen Stata sees foreach it knows that the next word (color) is the name of the macro it will use inside the loop. The word in signals that what follows is a generic list–we’ll explore some other kinds of lists later. The list items are separated by spaces. (If you ever need to have spaces inside a list item, put the item in quotes.) Thus this list consists of three elements, the words red, blue, and green. The { marks the beginning of the loop, and } marks the end. { must go at the end of the line that started with foreach, and } must go at the beginning of a new line.
Once Stata has interpreted the foreach command itself, it puts the first item in the macro, so color contains red. It then executes all the code inside the loop, in this case displaying red on the screen. When it reaches the } it jumps back up to the top of the loop, puts blue in color, and runs the code inside the loop again, displaying blue on the screen. Finally it repeats the process with green in color but, recognizing that’s the last item in the list, when it reaches } this time it quits when it reaches the end.
Note how the code inside the loop is indented. This is not required, but it is highly recommended as it makes the structure of the loop visually obvious. This is especially important once you have multiple levels of loops or other structures. Normally you’ll do this with Tab, but in the Stata do file editor, you can select all of your do file with Ctrl-a, then click Edit, Advanced, Re-indent to have Stata indent your code for you. This is actually a useful debugging tool: it can be hard to see if you forget a }, for example, but re-indenting the code will make the problem obvious.
Time to fulfill the promise made in the introduction and show you how to do the same thing to ten variables without writing it out ten times (though we won’t go as far as ten). Suppose you have several outcomes of interest and want to run regressions predicting each of them, with the same predictors in each model. This is a perfect job for a foreach loop:
foreach yvar in mpg price displacement {
display _newline(1) "Model for `yvar'"
reg `yvar' weight i.foreign
}
Model for mpg
Source | SS df MS Number of obs = 74
-------------+---------------------------------- F(2, 71) = 69.75
Model | 1619.2877 2 809.643849 Prob > F = 0.0000
Residual | 824.171761 71 11.608053 R-squared = 0.6627
-------------+---------------------------------- Adj R-squared = 0.6532
Total | 2443.45946 73 33.4720474 Root MSE = 3.4071
------------------------------------------------------------------------------
mpg | Coefficient Std. err. t P>|t| [95% conf. interval]
-------------+----------------------------------------------------------------
weight | -.0065879 .0006371 -10.34 0.000 -.0078583 -.0053175
|
foreign |
Foreign | -1.650029 1.075994 -1.53 0.130 -3.7955 .4954422
_cons | 41.6797 2.165547 19.25 0.000 37.36172 45.99768
------------------------------------------------------------------------------
Model for price
Source | SS df MS Number of obs = 74
-------------+---------------------------------- F(2, 71) = 35.35
Model | 316859273 2 158429637 Prob > F = 0.0000
Residual | 318206123 71 4481776.38 R-squared = 0.4989
-------------+---------------------------------- Adj R-squared = 0.4848
Total | 635065396 73 8699525.97 Root MSE = 2117
------------------------------------------------------------------------------
price | Coefficient Std. err. t P>|t| [95% conf. interval]
-------------+----------------------------------------------------------------
weight | 3.320737 .3958784 8.39 0.000 2.531378 4.110096
|
foreign |
Foreign | 3637.001 668.583 5.44 0.000 2303.885 4970.118
_cons | -4942.844 1345.591 -3.67 0.000 -7625.876 -2259.812
------------------------------------------------------------------------------
Model for displacement
Source | SS df MS Number of obs = 74
-------------+---------------------------------- F(2, 71) = 152.85
Model | 499643.527 2 249821.763 Prob > F = 0.0000
Residual | 116043.933 71 1634.42159 R-squared = 0.8115
-------------+---------------------------------- Adj R-squared = 0.8062
Total | 615687.459 73 8434.07479 Root MSE = 40.428
------------------------------------------------------------------------------
displacement | Coefficient Std. err. t P>|t| [95% conf. interval]
-------------+----------------------------------------------------------------
weight | .0967549 .0075599 12.80 0.000 .0816807 .111829
|
foreign |
Foreign | -25.6127 12.76769 -2.01 0.049 -51.07074 -.1546505
_cons | -87.23548 25.69627 -3.39 0.001 -138.4724 -35.99858
------------------------------------------------------------------------------The display command labels the output. _newline(1) prompts Stata to insert one blank line between each model just for readability.
Use a loop to run t-tests on mpg, weight, and displacement by foreign. Hint: to do this for a single variable you’d run:
ttest mpg, by(foreign)
Two-sample t test with equal variances
------------------------------------------------------------------------------
Group | Obs Mean Std. err. Std. dev. [95% conf. interval]
---------+--------------------------------------------------------------------
Domestic | 52 19.82692 .657777 4.743297 18.50638 21.14747
Foreign | 22 24.77273 1.40951 6.611187 21.84149 27.70396
---------+--------------------------------------------------------------------
Combined | 74 21.2973 .6725511 5.785503 19.9569 22.63769
---------+--------------------------------------------------------------------
diff | -4.945804 1.362162 -7.661225 -2.230384
------------------------------------------------------------------------------
diff = mean(Domestic) - mean(Foreign) t = -3.6308
H0: diff = 0 Degrees of freedom = 72
Ha: diff < 0 Ha: diff != 0 Ha: diff > 0
Pr(T < t) = 0.0003 Pr(|T| > |t|) = 0.0005 Pr(T > t) = 0.9997foreach var in mpg weight displacement {
display _newline(1) "T-test of `var'"
ttest `var', by(foreign)
}
T-test of mpg
Two-sample t test with equal variances
------------------------------------------------------------------------------
Group | Obs Mean Std. err. Std. dev. [95% conf. interval]
---------+--------------------------------------------------------------------
Domestic | 52 19.82692 .657777 4.743297 18.50638 21.14747
Foreign | 22 24.77273 1.40951 6.611187 21.84149 27.70396
---------+--------------------------------------------------------------------
Combined | 74 21.2973 .6725511 5.785503 19.9569 22.63769
---------+--------------------------------------------------------------------
diff | -4.945804 1.362162 -7.661225 -2.230384
------------------------------------------------------------------------------
diff = mean(Domestic) - mean(Foreign) t = -3.6308
H0: diff = 0 Degrees of freedom = 72
Ha: diff < 0 Ha: diff != 0 Ha: diff > 0
Pr(T < t) = 0.0003 Pr(|T| > |t|) = 0.0005 Pr(T > t) = 0.9997
T-test of weight
Two-sample t test with equal variances
------------------------------------------------------------------------------
Group | Obs Mean Std. err. Std. dev. [95% conf. interval]
---------+--------------------------------------------------------------------
Domestic | 52 3317.115 96.4296 695.3637 3123.525 3510.706
Foreign | 22 2315.909 92.31665 433.0035 2123.926 2507.892
---------+--------------------------------------------------------------------
Combined | 74 3019.459 90.34692 777.1936 2839.398 3199.521
---------+--------------------------------------------------------------------
diff | 1001.206 160.2876 681.6788 1320.734
------------------------------------------------------------------------------
diff = mean(Domestic) - mean(Foreign) t = 6.2463
H0: diff = 0 Degrees of freedom = 72
Ha: diff < 0 Ha: diff != 0 Ha: diff > 0
Pr(T < t) = 1.0000 Pr(|T| > |t|) = 0.0000 Pr(T > t) = 0.0000
T-test of displacement
Two-sample t test with equal variances
------------------------------------------------------------------------------
Group | Obs Mean Std. err. Std. dev. [95% conf. interval]
---------+--------------------------------------------------------------------
Domestic | 52 233.7115 11.82385 85.26299 209.9742 257.4489
Foreign | 22 111.2273 5.304548 24.88054 100.1959 122.2587
---------+--------------------------------------------------------------------
Combined | 74 197.2973 10.67586 91.83722 176.0203 218.5743
---------+--------------------------------------------------------------------
diff | 122.4843 18.56802 85.46959 159.4989
------------------------------------------------------------------------------
diff = mean(Domestic) - mean(Foreign) t = 6.5965
H0: diff = 0 Degrees of freedom = 72
Ha: diff < 0 Ha: diff != 0 Ha: diff > 0
Pr(T < t) = 1.0000 Pr(|T| > |t|) = 0.0000 Pr(T > t) = 0.0000You can use Stata’s variable list syntax (type help varlist if you’re not familiar with it) to specify a list of variables to loop over without naming each one. You just have to tell foreach that you’re using a varlist. You do that by changing the in in the foreach command to of. Then Stata understands that that the next word after in is not the first item in the list, but the kind of list you’re using:
foreach yvar of varlist price-rep78 {
display _newline(1) "Model for `yvar'"
reg `yvar' weight i.foreign
}
Model for price
Source | SS df MS Number of obs = 74
-------------+---------------------------------- F(2, 71) = 35.35
Model | 316859273 2 158429637 Prob > F = 0.0000
Residual | 318206123 71 4481776.38 R-squared = 0.4989
-------------+---------------------------------- Adj R-squared = 0.4848
Total | 635065396 73 8699525.97 Root MSE = 2117
------------------------------------------------------------------------------
price | Coefficient Std. err. t P>|t| [95% conf. interval]
-------------+----------------------------------------------------------------
weight | 3.320737 .3958784 8.39 0.000 2.531378 4.110096
|
foreign |
Foreign | 3637.001 668.583 5.44 0.000 2303.885 4970.118
_cons | -4942.844 1345.591 -3.67 0.000 -7625.876 -2259.812
------------------------------------------------------------------------------
Model for mpg
Source | SS df MS Number of obs = 74
-------------+---------------------------------- F(2, 71) = 69.75
Model | 1619.2877 2 809.643849 Prob > F = 0.0000
Residual | 824.171761 71 11.608053 R-squared = 0.6627
-------------+---------------------------------- Adj R-squared = 0.6532
Total | 2443.45946 73 33.4720474 Root MSE = 3.4071
------------------------------------------------------------------------------
mpg | Coefficient Std. err. t P>|t| [95% conf. interval]
-------------+----------------------------------------------------------------
weight | -.0065879 .0006371 -10.34 0.000 -.0078583 -.0053175
|
foreign |
Foreign | -1.650029 1.075994 -1.53 0.130 -3.7955 .4954422
_cons | 41.6797 2.165547 19.25 0.000 37.36172 45.99768
------------------------------------------------------------------------------
Model for rep78
Source | SS df MS Number of obs = 69
-------------+---------------------------------- F(2, 66) = 17.87
Model | 23.4089063 2 11.7044532 Prob > F = 0.0000
Residual | 43.2287748 66 .654981437 R-squared = 0.3513
-------------+---------------------------------- Adj R-squared = 0.3316
Total | 66.6376812 68 .979965899 Root MSE = .80931
------------------------------------------------------------------------------
rep78 | Coefficient Std. err. t P>|t| [95% conf. interval]
-------------+----------------------------------------------------------------
weight | -.0000381 .0001622 -0.23 0.815 -.0003618 .0002857
|
foreign |
Foreign | 1.22281 .277386 4.41 0.000 .6689911 1.776629
_cons | 3.149077 .5585605 5.64 0.000 2.033875 4.264279
------------------------------------------------------------------------------Since you specified of varlist, Stata understands that what follows, price-rep78 is a variable list consisting of all the variables from price to rep78. It expands that to price, mpg, and rep78 before starting the loop.
rep78 is an ordered categorical variable so OLS regression is a bad model for it.
Demean all the variables whose names start with t. You can select them with the varlist t*. You can demean a variable x by running:
sum x
replace x = x - r(mean)foreach var of varlist t* {
sum `var'
replace `var' = `var' - r(mean)
}
sum t*
Variable | Obs Mean Std. dev. Min Max
-------------+---------------------------------------------------------
trunk | 74 13.75676 4.277404 5 23
variable trunk was int now float
(74 real changes made)
Variable | Obs Mean Std. dev. Min Max
-------------+---------------------------------------------------------
turn | 74 39.64865 4.399354 31 51
variable turn was int now float
(74 real changes made)
Variable | Obs Mean Std. dev. Min Max
-------------+---------------------------------------------------------
trunk | 74 -2.42e-08 4.277404 -8.756757 9.243243
turn | 74 -4.43e-08 4.399354 -8.648648 11.35135The new mean isn’t exactly zero due to rounding.
A forvalues loop is similar to a foreach loop, but instead of specifying a list of items to loop over you specify a range of numbers:
forvalues i=1/5 {
display `i'
}1
2
3
4
5In this context, 1/5 is understood as not one divided by five, but a numlist containing the integers from one to five. (Type help numlist to learn how to specify more complicated lists of numbers.)
The following examples rely on example data files. Get them with:
net get loops, from(https://sscc.wisc.edu/sscc/stata) replacechecking loops consistency and verifying not already installed...
all files already exist and are up to date.The files will go in your working directory, so you may want to make an empty folder and use cd to make it the working directory first.
A very common use use for looping over numbers is variable names that essentially contain subscripts, such as wide from data. Consider the data set years.dta:
clear
use years
list in 1/2
+----------------------------------------------------------------+
1. | id | inc2000 | inc2001 | inc2002 | inc2003 | inc2004 | inc2005 |
| 1 | 39423 | 48624 | 49890 | 44589 | 42720 | 55447 |
|----------------------------------------------------------------|
| inc2006 | inc2007 | inc2008 | inc2009 | inc2010 |
| 47165 | 52524 | 49459 | 45258 | 61341 |
+----------------------------------------------------------------+
+----------------------------------------------------------------+
2. | id | inc2000 | inc2001 | inc2002 | inc2003 | inc2004 | inc2005 |
| 2 | 56113 | 50157 | 44083 | 46379 | 0 | 53811 |
|----------------------------------------------------------------|
| inc2006 | inc2007 | inc2008 | inc2009 | inc2010 |
| 49110 | 57407 | 53665 | 0 | 42368 |
+----------------------------------------------------------------+This is (made up) panel data in wide form where subjects were observed from 2000 to 2010 and their annual income recorded. Note that some subjects have zero income in some years. Suppose you needed to create an indicator variable for each year which is 1 if the subject’s income is greater than zero and 0 otherwise. Clearly this is a job for a loop.
A good way to start writing a loop is to write out the code for doing the task once. Here’s how you could create an indicator for the year 2000:
gen had_inc_2000 = (inc2000>0)What exactly needs to change to repeat the process for 2001? The number 2000 needs to change to 2001 in both the name of the variable to be created and the name of the income variable used in the condition after the equals sign. That tells you what parts of the command need to be replaced by macros when you convert it to a loop. It also tells you that you need to loop over years, which are numbers. This is a job for forvalues:
forvalues year = 2000/2010 {
gen had_inc_`year' = (inc`year'>0)
}
list in 2
+-----------------------------------------------------------------------+
2. | id | inc2000 | inc2001 | inc2002 | inc2003 | inc2004 | inc2005 |
| 2 | 56113 | 50157 | 44083 | 46379 | 0 | 53811 |
|-------------------------------------------------+----------+----------|
| inc2006 | inc2007 | inc2008 | inc2009 | inc2010 | had~2000 | had~2001 |
| 49110 | 57407 | 53665 | 0 | 42368 | 1 | 1 |
|-----------------------------------------------------------------------|
| had~2002 | had~2003 | had~2004 | had~2005 | had~2006 | had~2007 |
| 1 | 1 | 0 | 1 | 1 | 1 |
|-----------------------+-----------------------+-----------------------|
| had~2008 | had~2009 | had~2010 |
| 1 | 0 | 1 |
+-----------------------------------------------------------------------+What if the years had gone from 1995 to 2005? forvalues would be perfectly happy with 1995/2005. However, it would not be okay with two digit years: 95/05. Stata has the funny idea that the number after 99 is 100, not 00. Always use four digit years so you don’t create a Y2K problem for yourself more than 20 years into the new millennium.
Create variables containing standardized income (i.e. income with mean 0 and standard deviation 1). You can do so using the std() egen function.
forvalues year = 2000/2010 {
egen std_inc`year' = std(inc`year')
}
sum std_inc*
Variable | Obs Mean Std. dev. Min Max
-------------+---------------------------------------------------------
std_inc2000 | 10 4.47e-09 1 -2.714631 .6478793
std_inc2001 | 10 1.12e-08 1 -2.757327 .6340435
std_inc2002 | 10 -1.49e-09 1 -1.833925 1.351067
std_inc2003 | 10 -1.02e-08 1 -2.806168 .587041
std_inc2004 | 10 0 1 -1.40919 1.081572
-------------+---------------------------------------------------------
std_inc2005 | 10 4.47e-09 1 -1.83879 .8026543
std_inc2006 | 10 -7.45e-10 1 -1.230949 1.949251
std_inc2007 | 10 5.59e-09 1 -2.791434 .740059
std_inc2008 | 10 -8.27e-09 1 -2.798085 .5329422
std_inc2009 | 10 2.98e-09 1 -1.430534 .8174502
-------------+---------------------------------------------------------
std_inc2010 | 10 -1.49e-09 1 -2.678398 .9378194The example files include 10 CSV files, file1.csv through file10.csv. Each one is very simple and can easily be read into Stata by import delimited:
clear
import delimited file1.csv
list(encoding automatically selected: UTF-8)
(1 var, 10 obs)
+-----------+
| x |
|-----------|
1. | -.4618155 |
2. | 2.436316 |
3. | -.2123416 |
4. | -.8114582 |
5. | .0204311 |
|-----------|
6. | .9089745 |
7. | 1.000468 |
8. | .0400055 |
9. | 1.743336 |
10. | -.3708646 |
+-----------+Converting all ten files into Stata data sets is a job for a loop. But just to make things interesting, let’s stipulate that we want to combine the results into a single data set in long form. A typical real-world example might have multiple years of data with one file for each year. A critical component of hierarchical data in long form is a level one identifier, such as year. In this case we’ll use the file number (i.e. observations from file1.csv will be identified with a 1). Note that the files do not contain such a variable, so you’ll need to create it:
forvalues i = 1/10 {
clear
import delimited file`i'.csv
gen file = `i'
save file`i', replace
}(encoding automatically selected: UTF-8)
(1 var, 10 obs)
(file file1.dta not found)
file file1.dta saved
(encoding automatically selected: UTF-8)
(1 var, 10 obs)
(file file2.dta not found)
file file2.dta saved
(encoding automatically selected: UTF-8)
(1 var, 10 obs)
(file file3.dta not found)
file file3.dta saved
(encoding automatically selected: UTF-8)
(1 var, 10 obs)
(file file4.dta not found)
file file4.dta saved
(encoding automatically selected: UTF-8)
(1 var, 10 obs)
(file file5.dta not found)
file file5.dta saved
(encoding automatically selected: UTF-8)
(1 var, 10 obs)
(file file6.dta not found)
file file6.dta saved
(encoding automatically selected: UTF-8)
(1 var, 10 obs)
(file file7.dta not found)
file file7.dta saved
(encoding automatically selected: UTF-8)
(1 var, 10 obs)
(file file8.dta not found)
file file8.dta saved
(encoding automatically selected: UTF-8)
(1 var, 10 obs)
(file file9.dta not found)
file file9.dta saved
(encoding automatically selected: UTF-8)
(1 var, 10 obs)
(file file10.dta not found)
file file10.dta savedThat converted the ten files to Stata format, so now all we need to do is append them. The append command can act on a list of files, so there’s no need for a loop. But it would be tedious to list all ten files: append file1 file2 file3...
A macro function can put a list of files in a local macro we can then use in append. The official name is dir, which is followed by the name of the directory the files are in, in quotes. "." means the working directory. This is followed by the word files and then a pattern in quotes that describes the files you want to include in your list. That could be "*" for all files or "*.dta" for all Stata data sets. But we want just Stata data sets whose names start with file, so use "file*.dta".
Displaying the result is actually a bit tricky. Because file names can contain spaces, Stata puts quotes around each name. But that will confuse display. The solution is compound double quotes. If a string starts with a backtick followed by a double quote, Stata will understand the string doesn’t end until it sees double quotes followed by a right single quote.
local files: dir "." files "file*.dta"
display `"`files'"'"file1.dta" "file2.dta" "file3.dta" "file4.dta" "file5.dta" "file6.dta" "file7.
> dta" "file8.dta" "file9.dta" "file10.dta"Fortunately, you don’t have to worry about such things when you just want to use files:
clear
append using `files'
list in 6/15
+------------------+
| x file |
|------------------|
6. | .9089745 1 |
7. | 1.000468 1 |
8. | .0400055 1 |
9. | 1.743336 1 |
10. | -.3708646 1 |
|------------------|
11. | -.1547564 2 |
12. | -1.554458 2 |
13. | -.7080316 2 |
14. | -.0601965 2 |
15. | -.0790126 2 |
+------------------+Note that if you start with an empty data set, append will simply put together all the files listed in the append command.
Combining the files this way required reading each data set from CSV, writing it as a Stata data set, and then reading it again to append it. Reading and writing data from disk is one of the slowest things a modern computer does, and in a shared environment like the SSCC’s servers jobs doing a lot of reading and writing can slow down the system for everyone. It’s not a big deal with files of reasonable size, but if you find yourself in the world of “big data” you’ll want to do this more efficiently. For example, if you’re familiar with Stata data frames, you could use one to import each file, then immediately append it to another with no need to save it first and then read it again later.
Sometimes the list of things you want to loop over is contained in a local macro. You could just let the macro processor handle it:
foreach item in `my_list' {But the Stata developers realized they could improve performance by writing special code for handling macros into foreach. You can use it by using of local:
foreach item of local my_list {Note that my_list is not put in the usual quotes for a macro–the whole point is to bypass the usual macro processor.
When we converted the ten example CSV files, we took advantage of the fact that their names all contained a number so we could loop over those numbers. That wouldn’t work if the files had arbitrary names. But you can get a list of all the CSV files in a directory with:
local files: dir "." files "*.csv"You can then loop over them with:
foreach file of local files {The only trick is that rather than a macro i containing numbers like 1 that we can use in file names, you have a macro file containing the actual filename, like file1.csv. You could use string functions to extract the parts you want, but we’ll just accept it as is:
foreach file of local files {
clear
import delimited `file'
gen file = "`file'"
save `file'.dta, replace
}
local files: dir "." files "*.csv.dta"
clear
append using `files'
list in 6/15(encoding automatically selected: UTF-8)
(1 var, 10 obs)
(file file1.csv.dta not found)
file file1.csv.dta saved
(encoding automatically selected: UTF-8)
(1 var, 10 obs)
(file file10.csv.dta not found)
file file10.csv.dta saved
(encoding automatically selected: UTF-8)
(1 var, 10 obs)
(file file2.csv.dta not found)
file file2.csv.dta saved
(encoding automatically selected: UTF-8)
(1 var, 10 obs)
(file file3.csv.dta not found)
file file3.csv.dta saved
(encoding automatically selected: UTF-8)
(1 var, 10 obs)
(file file4.csv.dta not found)
file file4.csv.dta saved
(encoding automatically selected: UTF-8)
(1 var, 10 obs)
(file file5.csv.dta not found)
file file5.csv.dta saved
(encoding automatically selected: UTF-8)
(1 var, 10 obs)
(file file6.csv.dta not found)
file file6.csv.dta saved
(encoding automatically selected: UTF-8)
(1 var, 10 obs)
(file file7.csv.dta not found)
file file7.csv.dta saved
(encoding automatically selected: UTF-8)
(1 var, 10 obs)
(file file8.csv.dta not found)
file file8.csv.dta saved
(encoding automatically selected: UTF-8)
(1 var, 10 obs)
(file file9.csv.dta not found)
file file9.csv.dta saved
(variable file was str9, now str10 to accommodate using data's values)
+------------------------+
| x file |
|------------------------|
6. | .9089745 file1.csv |
7. | 1.000468 file1.csv |
8. | .0400055 file1.csv |
9. | 1.743336 file1.csv |
10. | -.3708646 file1.csv |
|------------------------|
11. | .0396736 file10.csv |
12. | .6678256 file10.csv |
13. | -1.162821 file10.csv |
14. | -1.585099 file10.csv |
15. | -.0959236 file10.csv |
+------------------------+Note how file is now a string containing the actual name of the source data file. Also, the individual files in Stata format are now file1.csv.dta, file2.csv.dta, etc. Having two file extensions may look strange–especially if your computer is set to not display file extensions. But Stata doesn’t mind at all. It wouldn’t take much work to change it if it bothers you.
The levelsof command gives you a list of all the levels, or values, of a variable. (If you specify a subset of the data, it will only include levels that appear in that subset.) With the local() option it will put that list in a local macro you can then loop over.
Consider the friends data set:
clear
use friends
list in 1/5
+--------------------------------------------------------+
| id friendA friendB friendC friendD friendE |
|--------------------------------------------------------|
1. | 1349 6374 9628 2527 1349 3903 |
2. | 2527 4349 3903 4349 4661 5605 |
3. | 2842 8043 1349 2527 4180 9774 |
4. | 3903 4373 1349 6226 4404 9112 |
5. | 3937 9628 3903 7971 9628 2842 |
+--------------------------------------------------------+This is made up data where students in a school are asked to name their five best friends. To carry out network analysis on this data, you might need to convert it into a matrix where there is one row for each student and one column for each student. A cell will have a 1 if the row student named the column student as a friend and a 0 otherwise. For example, the row for student 1349 will have a 1 in the column for student 6374.
If we only consider friendA for the moment, you could create the column for student 6374 with:
gen f6374 = (friendA==6374)To create the column for a different student we need to replace the id number in the two places it appears. But that means we need to loop over all the id numbers in the data set. This is a job for levelsof:
levelsof id, local(ids)1349 2527 2842 3903 3937 4180 4349 4373 4404 4661 4669 5136 5605 6226 6374 6484
> 7700 7819 7971 8043 8603 9112 9628 9774 9825We can now loop over ids to create and set a column for each student in the data set:
foreach id of local ids {
gen f`id' = (friendA==`id')
}
list in 1
+------------------------------------------------------------------------+
1. | id | friendA | friendB | friendC | friendD | friendE | f1349 | f2527 |
| 1349 | 6374 | 9628 | 2527 | 1349 | 3903 | 0 | 0 |
|------------------------------------------------------------------------|
| f2842 | f3903 | f3937 | f4180 | f4349 | f4373 | f4404 | f4661 | f4669 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
|-------+-------+-------+-------+-------+-------+-------+-------+--------|
| f5136 | f5605 | f6226 | f6374 | f6484 | f7700 | f7819 | f7971 | f8043 |
| 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
|------------------------------------------------------------------------|
| f8603 | f9112 | f9628 | f9774 | f9825 |
| 0 | 0 | 0 | 0 | 0 |
+------------------------------------------------------------------------+That takes care of friendA, but what about the other four friends? How can we combine this loop with a loop over the five friends?
The answer is a nested loop, or a loop within a loop. For example:
forvalues i=1/3 {
forvalues j=1/3 {
display "i=`i', j=`j'"
}
}i=1, j=1
i=1, j=2
i=1, j=3
i=2, j=1
i=2, j=2
i=2, j=3
i=3, j=1
i=3, j=2
i=3, j=3Note the order in which the loops are executed. First Stata starts the outer i loop, setting i to 1. It then starts the inner j loop, setting j to 1. When it reaches the end of the inner loop, it jumps back up to the top of just the inner loop. It then sets j to 2 but leaves i still set to 1. Only when it has finished all the elements of the inner loop does it jump to the top of the outer loop and set i to 2–but then it starts the inner loop all over again from 1.
There are two complications when we apply this to our loop over friends. First, if we create all the columns with gen while looking at friendA, we can’t create them again while looking at friendB. We need to create them once with gen and change them with replace. Second, if someone listed the person of interest as friendA so their column has a 1, we don’t want to set it to 0 just because the person is not also friendB. We only want to change 0 to 1, never 1 to 0.
Reload the data so you can start over, but you don’t need to recreate the list of id levels. Loop over the list of levels, create a column for each, and then start a loop over all the variables that start with friend. Inside that loop, change the new column to 1 if the friend variable contains that student’s id:
clear
use friends
foreach id of local ids {
gen f`id' = 0
foreach friend of varlist friend* {
quietly replace f`id' = 1 if `friend'==`id'
}
}
list in 1
+------------------------------------------------------------------------+
1. | id | friendA | friendB | friendC | friendD | friendE | f1349 | f2527 |
| 1349 | 6374 | 9628 | 2527 | 1349 | 3903 | 1 | 1 |
|------------------------------------------------------------------------|
| f2842 | f3903 | f3937 | f4180 | f4349 | f4373 | f4404 | f4661 | f4669 |
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
|-------+-------+-------+-------+-------+-------+-------+-------+--------|
| f5136 | f5605 | f6226 | f6374 | f6484 | f7700 | f7819 | f7971 | f8043 |
| 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
|------------------------------------------------------------------------|
| f8603 | f9112 | f9628 | f9774 | f9825 |
| 0 | 0 | 1 | 0 | 0 |
+------------------------------------------------------------------------+(The quietly prefix just prevents replace from cluttering up the web book with a bunch of (1 real change made) messages.)
You can use forvalues to loop over observations. Recall that _N is the number of observations in the data set (which can be used in macro expressions), _n is the observation number of the current observation, and x[i] means “the value of x for observation i”. So you could write:
gen new_id = .
forvalues i = 1/`=_N' {
quietly replace new_id = id[`i'] if _n==`i'
}
list id new_id in 1/5(25 missing values generated)
+---------------+
| id new_id |
|---------------|
1. | 1349 1349 |
2. | 2527 2527 |
3. | 2842 2842 |
4. | 3903 3903 |
5. | 3937 3937 |
+---------------+Of course there’s a far easier way to do this:
gen new_id = idThis highlights that many Stata commands are already loops over observations, and those implicit loops will be much faster than a loop over observations you might write. So if you find yourself tempted to write a loop over observations, look for a way to take advantage of Stata’s implicit loops instead.
Sometimes that may involve restructuring your data. Recall that with the years data you had to loop over years to create an indicator for “the subject had income in this year.” If you restructure the data from wide form to long form, then there’s a single variable for income and the years become observations, so a single gen command takes care of all the years just by looping over observations.
Sometimes you need to loop over two lists at the same time. Consider the months data set:
clear
use months
list in 1/3
+----------------------------------------------------------+
| id incJan incFeb incMar incApr incMay incJun |
|----------------------------------------------------------|
1. | 1 5208 6337 0 5820 4722 5082 |
2. | 2 5754 0 4886 4043 4882 5170 |
3. | 3 4453 5651 5548 0 4789 5197 |
+----------------------------------------------------------+This is very similar to the years data set, but each subject was observed once per month. It would be convenient to change the variable names to inc1, inc2, etc. so you can loop over them by number.
rename incJan inc1But changing February’s income requires changing both the month name (Jan to Feb) and the month number (1 to 2). Thus this requires looping over a list of month names and a list of month numbers at the same time. How can you do that?
One way is to loop over the month names, but keep track of a counter i in a separate local macro. When you’re done processing a month and are ready to move on to the next one, increase i by one as well:
local i 1
foreach month in Jan Feb Mar Apr May Jun {
rename inc`month' inc`i'
local i = `i'+1
}
list in 1/3
+----------------------------------------------+
| id inc1 inc2 inc3 inc4 inc5 inc6 |
|----------------------------------------------|
1. | 1 5208 6337 0 5820 4722 5082 |
2. | 2 5754 0 4886 4043 4882 5170 |
3. | 3 4453 5651 5548 0 4789 5197 |
+----------------------------------------------+Another approach is to loop over the numbers, but put a list of month names in a macro and use the word() function to pull out word i from the list:
clear
use months
local months Jan Feb Mar Apr May Jun
forvalues i = 1/6 {
local month = word("`months'", `i')
rename inc`month' inc`i'
}
list in 1/3
+----------------------------------------------+
| id inc1 inc2 inc3 inc4 inc5 inc6 |
|----------------------------------------------|
1. | 1 5208 6337 0 5820 4722 5082 |
2. | 2 5754 0 4886 4043 4882 5170 |
3. | 3 4453 5651 5548 0 4789 5197 |
+----------------------------------------------+You could skip creating the macro month and just use:
rename inc`=word("`months'", `i')' inc`i'But this is harder to read.
Macros are just strings, so you can use any of the string functions to work with them.
A variation on the first approach uses a foreach loop over a variable list to avoid having to list all the months:
foreach var of varlist incJan-incJun {Write a loop that uses the above foreach and then renames var. You’ll need a counter i like in the original. Remember to reload the data. If you’re not sure what var will contain, put a display command in the loop.
clear
use months
local i 1
foreach var of varlist incJan-incJun {
display "`var'"
rename `var' inc`i'
local i = `i'+1
}
list in 1/3incJan
incFeb
incMar
incApr
incMay
incJun
+----------------------------------------------+
| id inc1 inc2 inc3 inc4 inc5 inc6 |
|----------------------------------------------|
1. | 1 5208 6337 0 5820 4722 5082 |
2. | 2 5754 0 4886 4043 4882 5170 |
3. | 3 4453 5651 5548 0 4789 5197 |
+----------------------------------------------+All of these loops are processed sequentially. Doing the same thing to ten variables using a loop is faster for you than writing it out ten times, but it will take the computer the same amount of time either way. (Actually, the overhead required to set up the loop will make it just a bit slower, but not enough to worry about.) In today’s world where every computer has multiple cores, can the computer work on all ten variables at the same time?
Not easily. Stata MP will use multiple cores when it works on each variable, but it will still do one variable at a time. However, the SSCC’s Slurm cluster can run very large numbers of Stata jobs at the same time. So if you have to carry out a large number of tasks where 1) each task is independent of all the others, and 2) each task can save its work in a file or files that can be used by a different Stata job later, you can take advantage of the Slurm cluster to carry out, potentially, all the tasks at the same time. The best candidate of the examples we’ve done is the task of converting 10 CSV files to Stata files: you can easily split that up into ten jobs that can all run at the same time. Converting Stata Loops to Parallel Loops Using Slurm will show you how.