Running Matlab Parallel Server at the SSCC
Matlab Parallel Server goes a step beyond the Matlab Parallel Toolbox by letting you run Matlab jobs that use multiple servers. At the SSCC, Matlab Parallel Server runs workers on the SSCC’s Slurm cluster. That means you can easily put several hundred cores to work on your Matlab job, and on a quiet day a thousand or more.
The syntax to use Matlab Parallel Server is often identical to Matlab Parallel Toolbox, including the parpool() function and parfor loops. Note that you’ll run your job on Linstat, not Slurm: Matlab Parallel Server will take care of submitting the workers to the Slurm cluster as an array of jobs. The information needed to do so is stored in a cluster profile. The cluster profile includes settings that sometimes change between jobs, so you may want to create multiple profiles.
SSCC Staff have worked out how to run jobs using Matlab Parallel Server, but we don’t actually know Matlab and won’t be able to help you write code that uses it. If you’re not sure whether your job isn’t working because of a problem with the code or a problem with how you’re running it, feel free to ask and we’ll help as best we can.
Setting Up a Cluster Profile
To set up a cluster configuration, click the HOME tab at the very top, then find the group of buttons with the label ENVIRONMENT and click on Parallel and Create and Manage Clusters…
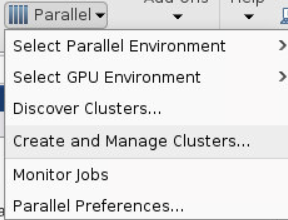
Then click Add Cluster Profile and select Slurm.
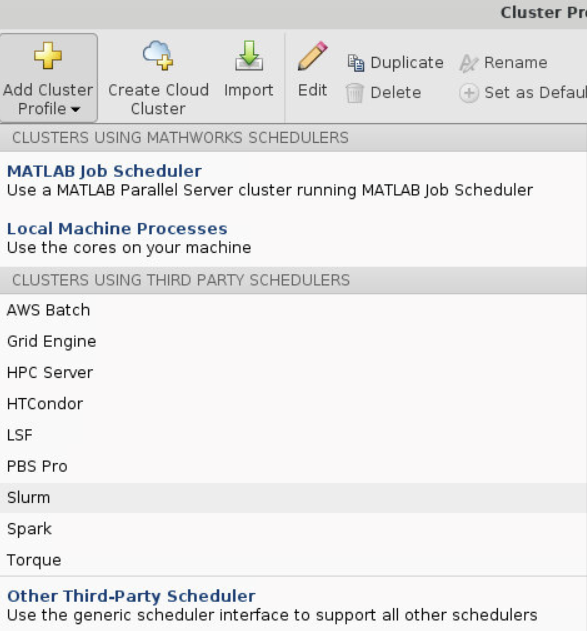
This will create a profile called SlurmProfile1 (you can change the name if you want to). You’ll refer to that name in your code.
The default configuration does not reserve enough memory to actually run, so you’ll need to increase it. To do so, click Edit.
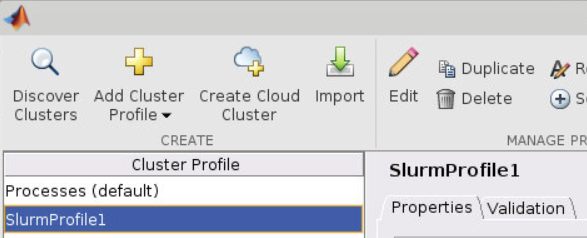
Scroll down to the section labeled Scheduler Plugin. This is where you can set Slurm properties, but note that the property names do not match what Slurm calls them. Click Add to add a new property.
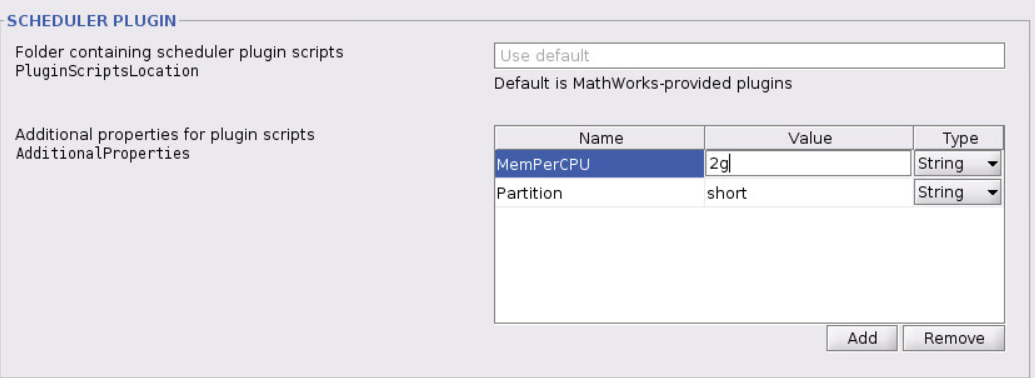
Add a MemPerCPU property and set it to at least 2g or the cluster won’t start at all. You may need more memory, depending on your program, but don’t reserve more memory than you need. Most of the servers in the cluster have 2GB of memory per core, so if you need more memory that will limit the number of cores (workers) you can use.
Add a Partition property and set it to the partition you want to use. If you’re not sure, use sscc. If any part of a job is preempted by a higher priority partition the whole job has to start over, so you may want to use a higher priority partition if you have access to one. The short partition lets you take advantage of the servers that are reserved for short jobs (less than 6 hours). See Partitions and Priorities for more information.
Running a Parallel Job
At this point you’ll have two entries under Cluster Profile on the left. Processes (Default) uses Matlab Parallel Toolbox to run workers on the server you’re on. SlurmProfile1 uses Matlab Parallel Server to run workers on the SSCC Slurm cluster. You specify which you want to use when you run parpool(). For example,
parpool('Processes', 16);
creates a pool of 16 workers on the server you’re on, while
parpool('SlurmProfile1', 256);
creates a pool of 256 workers on the SSCC Slurm cluster. (Starting a parallel pool is a slow process, so be patient.) The syntax for parfor is the same either way.
As an example, try downloading and running primefactors.m. This simple program demonstrates how to use the different kinds of parallel pools, and compares their performance. It will also ensure you’ve got the cluster profile set up properly. It will take several minutes to run.
You can run Matlab Parallel Server jobs using Matlab’s graphical user interface, but unless your job is very short you almost certainly want to run it in the background so it will keep going even if you log out or get disconnected. You can do that (like any other Matlab script) with:
matlab -nodisplay < my_script.m > my_script.log &
If you try to use more workers than the Slurm cluster can provide, your program will (eventually) crash, saying the parallel pool failed to start. The job will not wait in the Slurm queue until additional resources become available. Check what resources are available at the time you want to start your job using Slurm Status.